


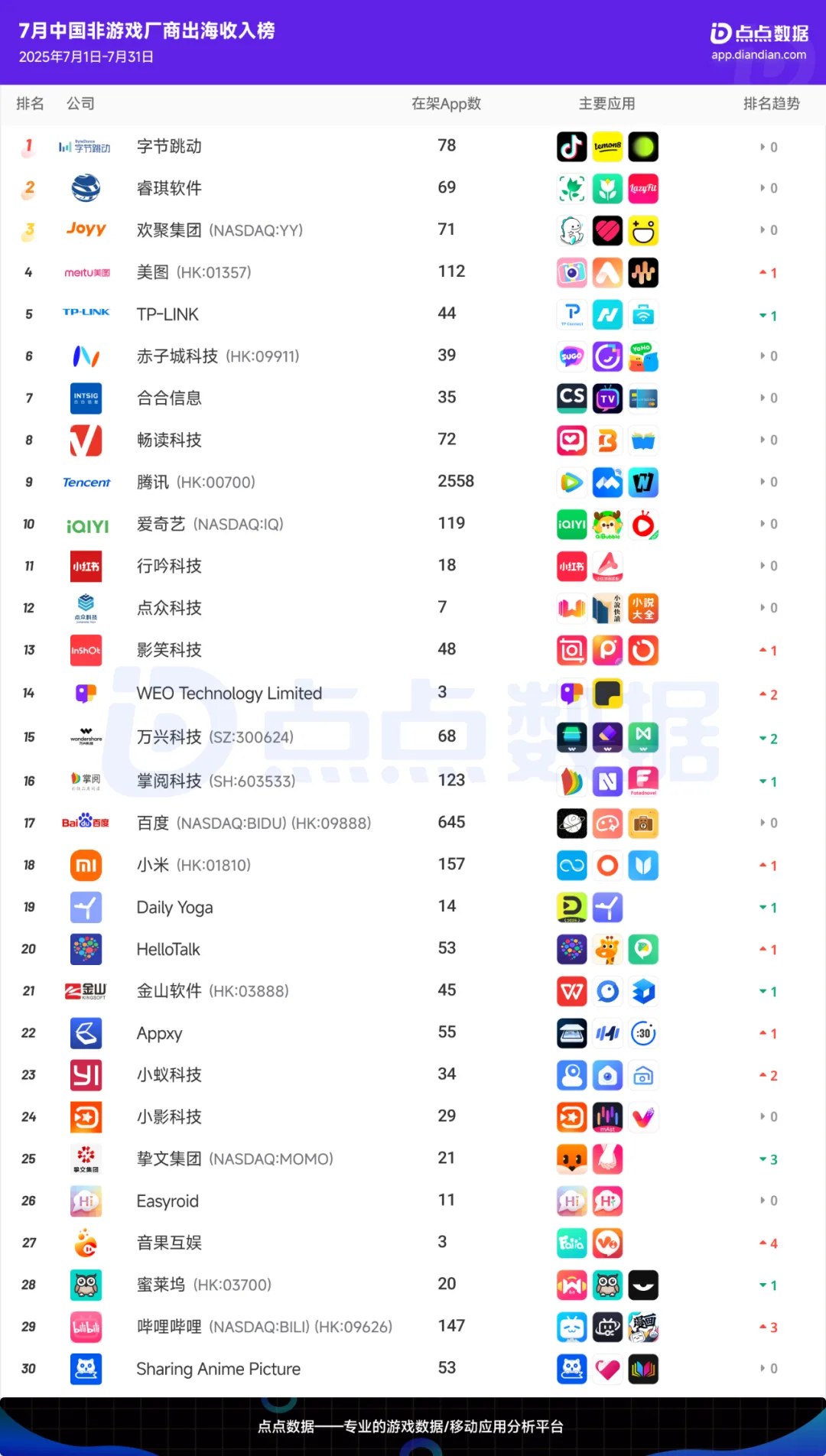
从GPU到ASIC
算力经济学走向分水岭
-
谷歌:博通为谷歌定制的TPU v5芯片在Llama-3推理场景中,单位算力成本较H100降低70%。
-
亚马逊:3nm制程的AWS Trainium 3,同等算力下能耗仅为通用GPU的1/3,年节省电费超千万美元;据了解,亚马逊Trainium芯片2024年出货量已超50万片。
-
微软:根据IDC数据,微软Azure自研ASIC后,硬件采购成本占比从75%降至58%,摆脱长期被动的议价困境。
图:市面主流GPU与ASIC算力成本对比 资料来源:西南证券
ASIC的“手术刀”
非核心模块,通通砍掉
谷歌TPU v5e AI加速器实拍
-
谷歌TPU v4中,95%的晶体管资源用于矩阵乘法单元和向量处理单元,专为神经网络计算优化,而GPU中类似单元的占比不足60%。
-
不同于传统冯·诺依曼架构的“计算-存储”分离模式,ASIC可围绕算法特征定制数据流。例如在博通为Meta定制的推荐系统芯片中,计算单元直接嵌入存储控制器周围,数据移动距离缩短70%,延迟降低至GPU的1/8。
-
针对AI模型中50%-90%的权重稀疏特性,亚马逊Trainium2芯片嵌入稀疏计算引擎,可跳过零值计算环节,理论性能提升300%。
“新地图”价值远不止1000亿美元
-
先进封装:台积电CoWoS产能的35%已转向ASIC客户,国产对应的中芯国际、长电科技、通富微电等。
-
云厂商英伟达硬件方案解耦带来的新硬件机会:如AEC铜缆,亚马逊自研单颗ASIC需配3根AEC,若2027年ASIC出货700万颗,对应市场超50亿美元,其他还包括服务器、PCB均是受益于相似逻辑。
产业链配套部分难度相对较低,对应的服务器、光模块、交换机、PCB、铜缆,由于技术难度低,国内企业本来竞争力就比较强。与此同时,这些产业链企业与国产算力属于“共生”关系,ASIC芯片产业链也不会缺席。
结语
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/32951.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 







































{kind=link}