


摘要
Claude Opus 4.1 49% 任务不输人类,GPT-5-high 40.6%,差距主要来自图表美观度而非实质能力。
GDPval-v0仅测“写报告”这一单点任务,未覆盖交互流程与实操环节,远未到取代程度。
15个月内从GPT-4o的13.7%跃升至40%+,OpenAI预计曲线将继续陡峭上升。
工具属性优先——帮专业人士节省时间,让其聚焦更高价值工作,而非直接替代人类岗位。
当地时间周四(9月25日),人工智能(AI)研究公司OpenAI发布了一项新的基准测试,用于比较其AI模型与各行业专业人士的工作表现。
这项测试名为GDPval,是一次初步尝试,旨在评估OpenAI的系统距离在经济价值工作上超越人类有多近。而经济价值工作是OpenAI开发通用人工智能(AGI)的关键环节。
OpenAI周四表示,其GPT-5模型以及竞争对手Anthropic公司的Claude Opus 4.1“已经接近行业专家的工作质量”。
这并不意味着OpenAI的模型会立刻取代人类工作。尽管一些CEO预测AI在几年内就会取代人类,但OpenAI承认GDPval目前只涵盖人们实际工作中有限的一部分任务。不过,这是该公司用来衡量AI向这一里程碑迈进的最新方式之一。
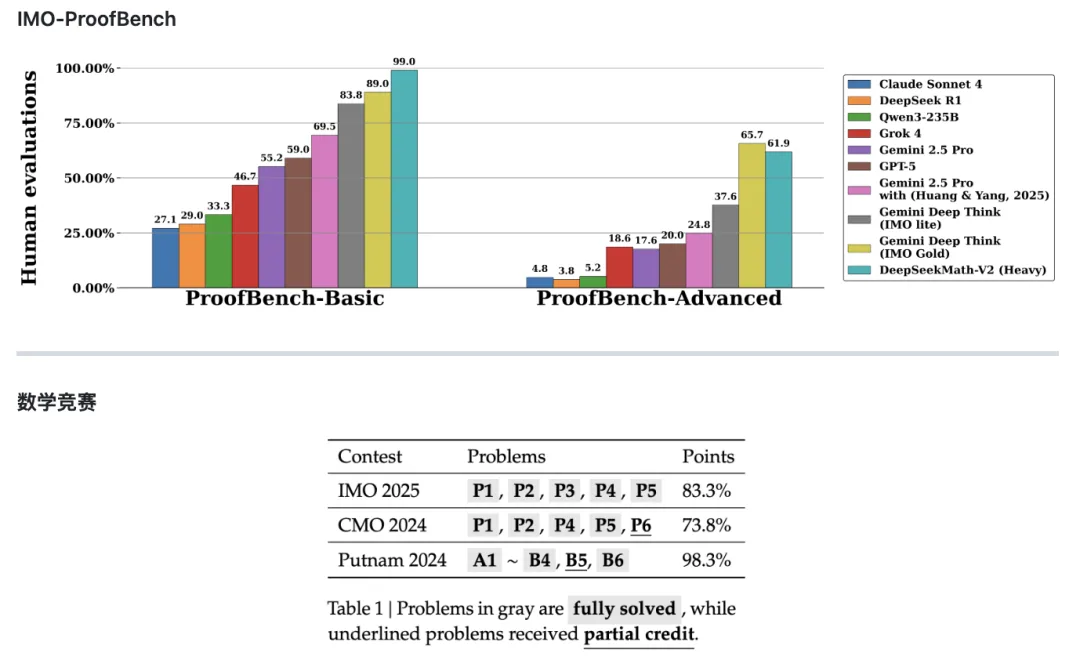
GDPval基于美国GDP贡献最大的九个行业,包括医疗、金融、制造业和政府等领域。测试覆盖了44种职业,从软件工程师到护士再到记者。
在首个版本GDPval-v0中,OpenAI邀请资深专业人士对比AI生成的报告与其他专业人士的成果,并挑选出更优者。
例如,某项任务要求投行人员为“最后一公里配送行业”制作竞争格局分析,并与AI生成的报告进行对比。OpenAI随后将AI模型在全部44个职业中对抗人类报告的“胜率”进行平均计算。
结果显示,GPT-5-high(高算力版本GPT-5)在40.6%的情况下被评为优于或与行业专家持平。
而Anthropic的Claude Opus 4.1模型则在49%的任务中被评为不输于行业专家,这一表现超过了OpenAI的模型。
OpenAI对此解释称,之所以Claude得分更高,部分原因是其倾向于生成更美观的图表,而非纯粹性能更优。
需要说明的是,大多数职业的工作远不止提交研究报告,而这却是GDPval-v0所测试的全部内容。OpenAI承认这一点,并计划在未来开发更全面的测试,涵盖更多行业和交互式工作流程。
尽管如此,OpenAI仍认为GDPval的进展具有重要意义。
OpenAI首席经济学家Aaron Chatterji在接受采访时表示,GDPval的测试结果表明,这些岗位上的人们可以利用AI模型节省时间,从而专注于更有意义的工作。
“因为模型在某些事情上已经变得很擅长,随着能力的提升,人们可以越来越多地把部分工作交给模型,去做潜在更有价值的事情,”Chatterji说。
OpenAI评估负责人Tejal Patwardhan表示,她对GDPval的进步速度感到鼓舞。
Patwardhan指出,约15个月前发布的GPT-4o模型得分仅为13.7%(胜出或持平人类),而GPT-5的成绩几乎提高了三倍。她预计这一趋势还会继续。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/66768.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





































{kind=link}