


在当下AI技术迅速发展的环境里,如何快速、高效地集成多模型并进行二次开发,成为了不少开发者关心的问题。我个人在实践中发现,OpenClaw提供了一个相当灵活的解决方案,它不仅支持多种主流AI模型,还提供了完整的API文档与集成指南,让开发者能够以较低的门槛进行快速上手。本文将带你深入了解OpenClaw的API架构、接入准备、集成步骤,以及如何在此基础上进行扩展和优化。我们会一步步拆解每个环节,同时分享一些我在实践中总结的经验和技巧。
OpenClaw API概述
API功能简介
说到OpenClaw的API功能,我个人觉得最令人惊讶的是它的模块化设计。换句话说,你不必一次性掌握全部接口,就能根据自己的需求灵活调用不同模型,比如Claude、OpenAI GPT甚至Google Gemini。它不仅提供文本处理能力,还有一些比较有意思的扩展接口,可以在聊天机器人、自动化任务等多种场景中应用。
有意思的是,OpenClaw不仅限于简单的API调用,它还支持Webhook和技能插件,这让我想到,如果你愿意深入开发,几乎可以把它打造成一个个人化的AI助手。实际上,这种设计让我在构建多平台应用时省了不少心。
支持的接口类型
OpenClaw提供了多种接口类型,我个人在使用时发现REST调用和Python SDK是最常用的两种方式。REST接口非常适合快速集成,尤其是和现有系统对接时;而Python SDK则方便做深度开发和接口封装,尤其是当你希望对调用逻辑进行高度自定义时。值得注意的是,这些接口的设计都遵循标准规范,使得学习成本相对较低,即便是刚入门的开发者,也能很快上手。
使用场景与优势
我个人认为,OpenClaw最适合的场景其实是那些需要跨平台、多模型灵活调用的应用。比如,你想在Telegram里实现一个智能问答机器人,同时在WhatsApp和Discord也能同步响应,这时候OpenClaw就显得非常方便。它的优势在于模块化和扩展性:你可以根据不同业务需求选择模型,也可以随时增加新的技能插件,几乎不会影响原有逻辑。
API接入准备
申请API Key与权限设置
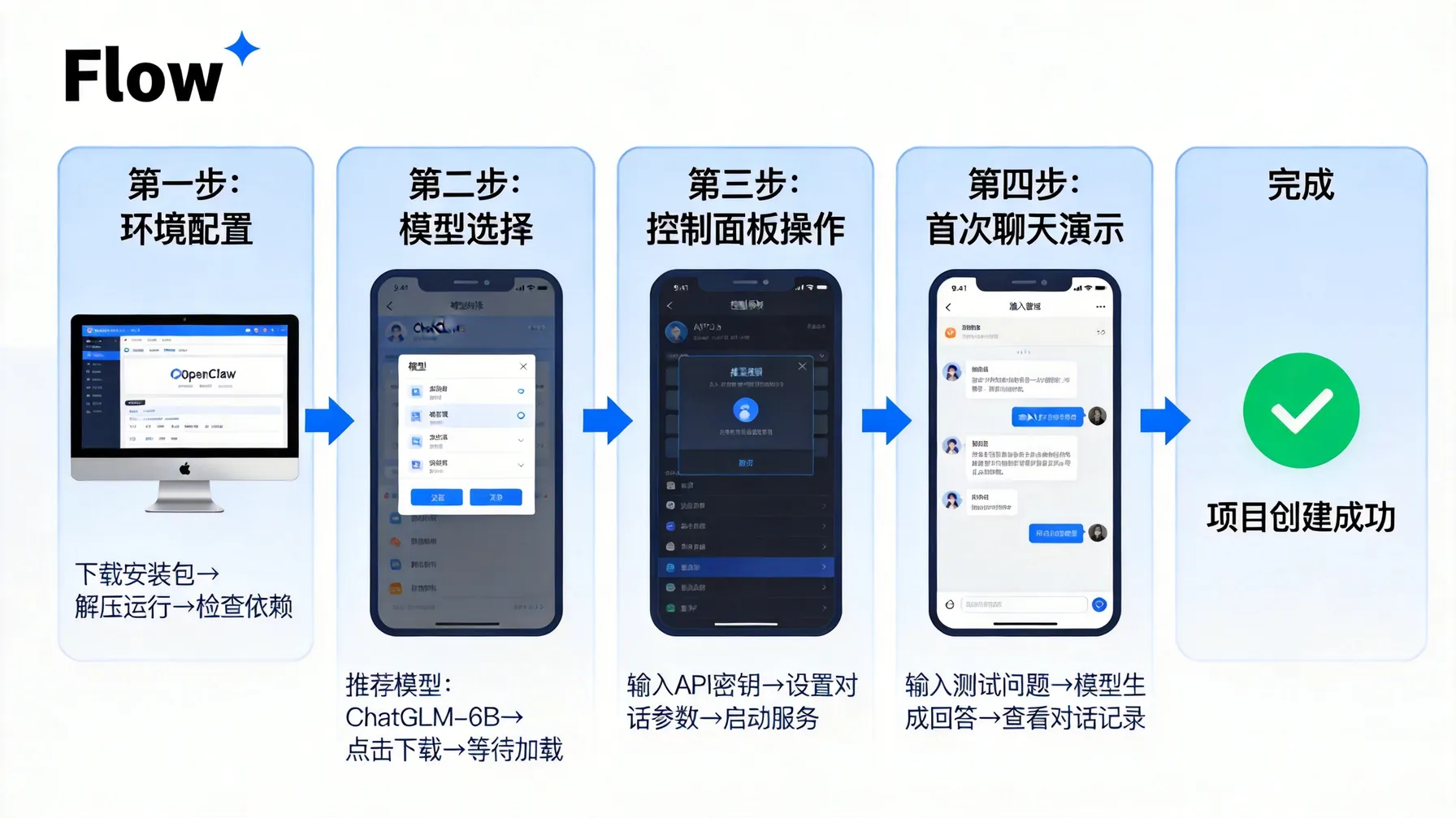
接入OpenClaw之前,第一步自然是申请API Key。说到这点,我个人的经验是,虽然流程不复杂,但一定要注意权限的配置。不同的模型或者接口可能需要不同权限,如果不提前规划,很容易在调用时遇到权限错误。顺便提一下,我一般会先在测试环境里申请一个低权限Key,等验证无误后再申请生产Key,这样可以避免不必要的安全风险。
开发环境要求
说到环境,我想强调一点:OpenClaw对Python的支持特别友好,但这并不意味着其他环境就完全不可行。实际上,你只要能发起HTTP请求,都可以调用其REST接口。不过,如果你打算做深度二次开发,建议使用Python 3.8以上版本,并安装常用的依赖库,比如requests和json等,这样才能充分利用SDK提供的功能。
基础依赖与工具安装
在我的实践中,安装基础依赖其实是个小问题,但千万不要忽视版本匹配。openclaw-sdk Python包是核心工具,它提供了丰富的示例和文档,让你可以快速理解接口调用方式。值得注意的是,如果你想整合Webhook或者技能插件,还需要额外配置一些HTTP服务器或调试工具,但整体来说,安装和配置过程相对直观。
API集成步骤
请求与响应格式说明
说到请求与响应,这部分我个人体会最深的是规范性的重要性。OpenClaw的接口遵循JSON标准,这让我在调试时减少了很多不必要的困扰。请求里通常包含模型选择、输入内容和一些可选参数,而响应中会返回结果文本、状态码以及调试信息。这个设计让我觉得非常直观,同时也便于后续日志记录和异常排查。
常用接口调用示例
有意思的是,官方提供的示例几乎覆盖了常见场景,我个人在最初接入时就直接参考了这些示例进行改造。无论是单模型调用还是多模型并行处理,你都能在示例里找到对应的方法。顺便说一句,如果你是第一次接触API,建议先在控制台测试调用,验证返回数据结构,这样可以节省不少调试时间。
错误码与异常处理
我个人认为,理解错误码比记住接口参数更重要。OpenClaw的错误码设计相对清晰,但在实际开发中,还是会遇到一些意料之外的网络或权限问题。我的做法是先分类处理:客户端错误、服务端错误、权限错误,然后针对每类错误写统一的处理逻辑,这样一旦出现异常,也能快速定位和解决。
二次开发指南
扩展功能开发思路
说到二次开发,我个人觉得最吸引人的是OpenClaw的可扩展性。比如,你可以在现有API基础上封装自己的功能模块,或者通过Webhook触发一些自动化任务。我曾尝试把它和内部CRM系统结合,结果发现仅用几行Python代码,就能让聊天机器人根据客户信息做出智能回复。这种灵活性,让我对平台的潜力有了更直观的感受。
接口封装与复用
在实际开发中,我发现封装接口是提高效率的关键。你不必每次都写重复代码,可以把常用的调用逻辑封装成函数或类,然后在不同项目中复用。这样不仅减少出错概率,还能让团队协作更加顺畅。或许有人会担心封装过度会增加维护成本,但我的经验是,合理设计接口层次,维护其实很轻松。
安全性与权限控制
这个问题没有简单的答案,但我个人的理解是,安全性要从两方面考虑:API Key管理和权限控制。要保证Key不泄露,同时在调用接口时遵循最小权限原则。对于企业项目而言,这一点尤其重要。我在实践中会结合环境变量和配置文件进行管理,这样即便多人协作,也能有效降低风险。
最佳实践与优化建议
性能优化技巧
性能优化对我来说,是一个不断试错的过程。OpenClaw的多模型调用支持并行处理,所以合理安排请求顺序和并发数量,可以明显提升响应速度。值得注意的是,有些模型对请求频率敏感,所以在设计调用逻辑时,我通常会加上一些限流策略,避免过度请求导致失败。
日志与监控策略
我个人很重视日志和监控,尤其是当系统规模变大后。OpenClaw提供了详细的返回信息,配合自建的日志系统,可以实时监控请求状态和性能指标。我的经验是,日志不仅是排错工具,更是优化依据。通过分析历史调用数据,你可以发现瓶颈所在,并持续改进。
版本更新与兼容性管理
版本更新有时令人头疼,但我个人的策略是保持依赖最小化,并定期跟踪OpenClaw的更新日志。这样可以提前发现潜在的不兼容问题。值得注意的是,SDK更新可能影响函数签名或返回格式,所以每次升级前,我都会先在测试环境验证,确保生产系统稳定。
常见问题与解决方案
集成常见错误解析
在我个人的开发经验里,最常见的错误往往不是接口本身,而是参数配置或权限问题。例如模型选择错误、请求格式不符合规范,或者Key权限不足。遇到这种情况,我通常会回到官方文档,再结合日志信息排查,这样几乎都能迎刃而解。
调试与排错方法
调试其实有点像侦探游戏,我个人喜欢先确认请求是否到达服务端,然后查看响应状态和返回内容。对于Python SDK来说,抓包和打印日志是最直接的方式;而REST接口调用,则可以借助Postman或者curl进行快速测试。值得注意的是,调试不仅是为了修复问题,也可以帮助你更深入理解API内部逻辑。
用户反馈与支持渠道
有意思的是,OpenClaw的社区支持和官方文档都相当完善。我个人经常通过官方论坛或GitHub提交问题,反馈一般都会得到及时响应。顺便提醒一下,及时收集用户反馈对于二次开发和功能优化非常重要,它能帮助你发现使用过程中不易察觉的问题,从而改进产品体验。
总体来看,OpenClaw不仅提供了稳定、高效的API接口,还具备强大的扩展能力,使得多模型、多平台集成变得相对容易。我个人的实践经验告诉我,掌握好API接入、接口封装与安全策略,再结合日志监控与性能优化,你就能充分发挥OpenClaw的潜力。希望本文能够为你的二次开发提供一些参考和思路,让复杂的集成工作变得可控而高效。
常见问题
OpenClaw API主要支持哪些AI模型?
OpenClaw采用模块化设计,可以接入多种主流AI模型,例如OpenAI GPT系列、Claude以及Google Gemini等。开发者可以根据需求选择不同模型,通过统一接口进行调用,从而在同一应用中实现多模型协同。
使用OpenClaw API需要具备哪些基础准备?
通常需要获取平台提供的API Key,并完成基本的开发环境配置,例如准备HTTP请求工具或Python运行环境。同时建议熟悉基础的REST接口调用方式,以便快速完成模型请求与返回数据处理。
REST接口和Python SDK有什么区别?
REST接口适合快速集成到现有系统中,通过标准HTTP请求即可完成调用;而Python SDK更适合深度开发和自动化任务,可以封装复杂逻辑并简化重复调用过程,在构建完整应用时更为灵活。
OpenClaw适合哪些应用场景?
该平台特别适用于需要同时调用多个AI模型的应用,例如智能客服、聊天机器人、多平台自动回复系统以及AI辅助工具。通过统一API接口,可以在Telegram、Discord或其他平台中实现一致的AI能力。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/72777.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















{kind=link}