


有时候我会发现,很多人第一次接触 OpenClaw 时,总会有点迷茫。工具本身其实并不复杂,但资源分散、学习路径不清晰,往往让人走了不少弯路。我自己刚开始接触的时候也是这样——到处找资料、看论坛帖子,甚至还翻了不少国外社区的讨论。慢慢地才意识到,其实只要找到合适的资源,再配合一些比较实用的学习方法,上手速度会快很多。
这篇文章,我想用一种比较轻松、接近聊天的方式,把目前能找到的一些 最新免费资源、学习资料以及我个人比较推荐的学习技巧整理出来。无论你是刚刚听说 OpenClaw,还是已经用了一段时间但想进一步提升效率,也许都能从中找到一些有用的线索。
OpenClaw简介
OpenClaw的核心功能
说到 OpenClaw,其实我第一次看到这个名字的时候,还以为它只是一个很小众的工具。后来真正深入了解之后才发现,它的功能其实相当丰富,而且有一种很明显的特点——开放性。
简单来说,OpenClaw更像是一个可扩展的平台,而不是一个单一的软件工具。它允许用户根据自己的需求进行扩展、定制,甚至重新设计某些功能模块。换句话说,你可以把它理解成一个“半成品工具箱”,而不是一把固定用途的锤子。
有意思的是,这种设计理念其实非常符合现在很多开发者的习惯。我们不再希望被一个封闭的软件限制,而是希望能自己动手做一些调整。OpenClaw在这一点上,确实给了用户不少自由空间。
当然,自由度高也意味着学习曲线稍微陡一点。刚开始可能会觉得界面有点复杂,但只要熟悉几个核心模块,整体逻辑其实挺清晰的。
适用人群与应用场景
很多人会问一个问题:OpenClaw到底适合谁?
这个问题其实没有一个特别标准的答案,不过根据我自己的观察,它主要被几类人使用得比较多。
- 对自动化工具感兴趣的开发者
- 希望优化工作流程的技术人员
- 喜欢折腾开源项目的学习者
- 需要灵活工具链的团队
如果你只是想找一个“一键完成任务”的工具,可能会觉得 OpenClaw 有点过于灵活。但如果你喜欢自己搭建系统、调整流程,那它其实挺有意思的。
说到这里,我突然想到一个朋友的例子。他最开始只是想用 OpenClaw 做一点简单的数据处理,结果后来慢慢扩展,最后甚至搭了一整套自动化工作流程。听起来有点夸张,但这确实是开源工具的魅力所在。
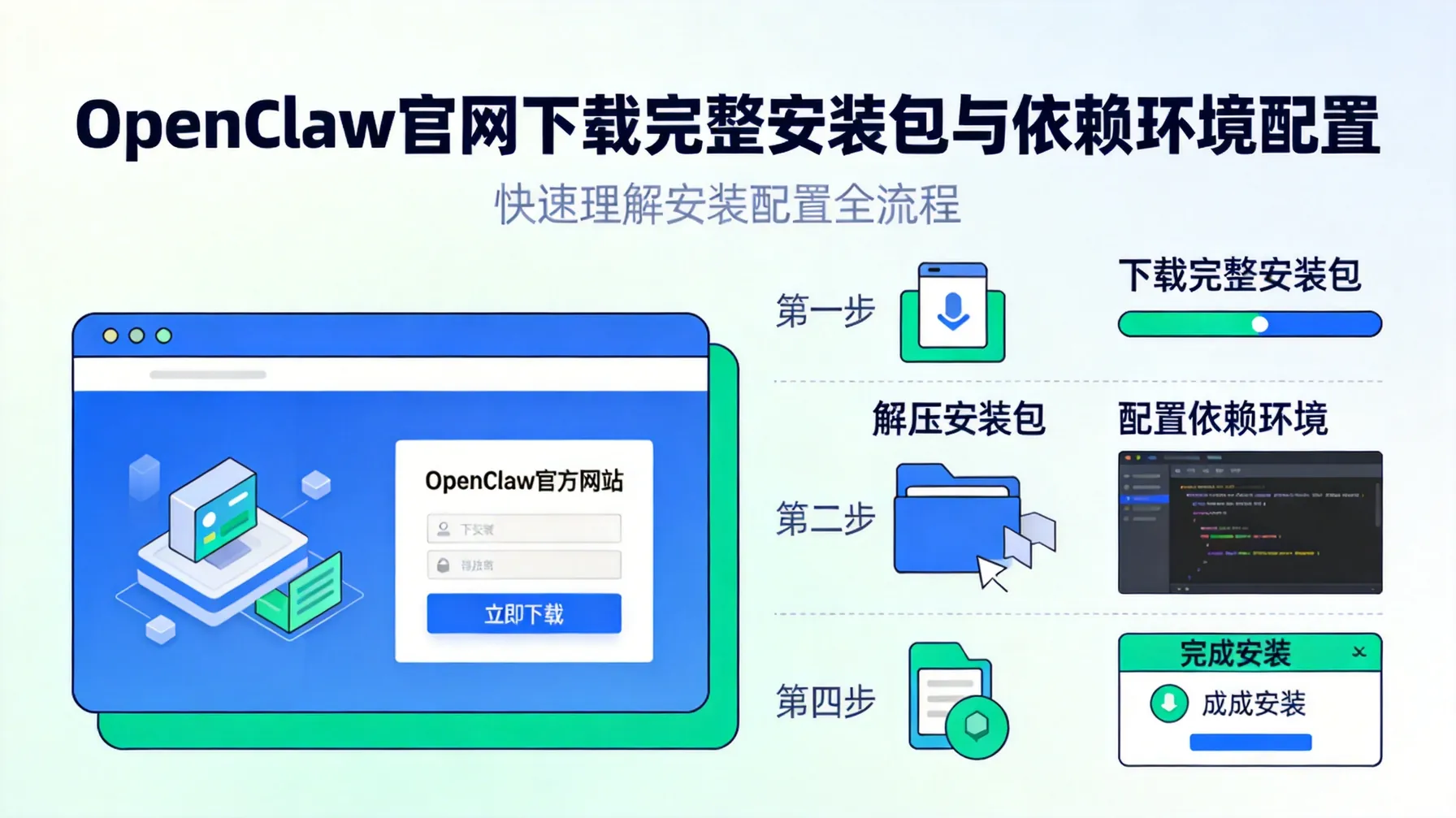
最新免费资源汇总
官方提供的免费资源
很多人学习工具的时候,第一反应是去搜教程视频。但老实说,我个人其实更建议先看官方资源。
原因很简单:官方资料通常最完整,而且更新也最及时。
目前 OpenClaw 官方提供的免费资源主要包括:
- 完整文档指南
- 基础功能演示
- API使用示例
- 开发者参考手册
有时候文档看起来会比较枯燥,不过如果你耐心看几章,很容易就能抓住核心思路。尤其是那些示例代码,其实非常值得多研究一下。
我自己就经常把示例项目下载下来,然后一边运行一边改代码。这个过程其实挺有帮助的。
社区共享的学习资料
如果说官方文档是“标准答案”,那社区资料就更像是各种经验分享。
有时候社区里的一篇帖子,甚至比一整本说明文档都更有用。为什么呢?因为它往往来自真实的使用场景。
比如在一些开源社区中,经常能看到这样的内容:
- 完整项目案例解析
- 配置经验分享
- 常见错误解决方法
- 工具组合使用技巧
我个人特别喜欢看别人分享的项目实践。有时候只是一个很小的技巧,就能帮你节省很多时间。
当然,社区内容也需要稍微筛选一下。毕竟每个人的环境和需求都不一样。
第三方插件与工具
说到 OpenClaw,一个很有意思的现象是:很多真正强大的功能,其实来自第三方插件。
这让我想到一句话——工具本身只是基础,生态才是关键。
目前比较常见的插件类型包括:
- 自动化扩展插件
- 数据处理模块
- 界面增强工具
- 集成开发辅助插件
不过这里要稍微提醒一句:插件虽然好用,但不要一开始就装太多。先把基础功能熟悉,再慢慢扩展,学习体验会更好。
高效学习OpenClaw的技巧
入门指南与快速上手方法
刚开始学习 OpenClaw 时,我其实也犯过一个很典型的错误——试图一次性学完所有功能。
后来发现,这种方法其实效率很低。
更好的方式其实是:
- 先理解核心概念
- 运行几个简单案例
- 尝试修改配置
- 逐步增加复杂度
换句话说,学习过程应该像搭积木一样,一块一块往上叠。
有时候我甚至会建议新手:先不要急着写项目,先花一天时间专门“乱点功能”。这种探索式学习其实挺有效的。
常见问题及解决方案
任何工具在使用过程中都会遇到问题,OpenClaw 也不例外。
比较常见的情况包括:
- 环境配置失败
- 插件冲突
- 版本兼容问题
- 配置文件错误
这里有一个小经验,我自己用了很多年——先看报错信息,再搜关键词。
很多问题其实早就有人遇到过,只要稍微查一下社区讨论,往往就能找到解决办法。
当然,有时候问题确实比较复杂,这时候就需要一点耐心了。
学习路径与阶段性目标
很多人学习工具的时候都会有一个困惑:到底什么时候算“学会了”?
其实我个人觉得,这个问题本身就有点不太合理。
工具这种东西,很难说有一个终点。更现实的方式是设定阶段目标,比如:
- 理解基本架构
- 完成第一个小项目
- 掌握插件扩展
- 尝试二次开发
每达到一个阶段,就意味着你的理解又深入了一点。
说实话,我自己到现在也还在不断学习新的用法。
实用案例与应用展示
初学者项目示例
如果你刚刚开始学习 OpenClaw,我通常会建议从一个非常简单的小项目开始。
比如说:
- 简单的数据处理任务
- 自动化脚本工具
- 基础任务调度系统
这些项目听起来可能很普通,但它们可以帮助你快速理解工具结构。
有时候,完成一个小项目带来的信心,比看十篇教程都更有价值。
进阶用户实践经验分享
当你已经熟悉基本功能之后,其实就可以尝试更复杂的应用了。
很多进阶用户会利用 OpenClaw 构建完整的自动化系统,比如:
- 数据分析流程
- 任务调度平台
- 自动化部署工具
说到这里,我印象很深的一件事是,有开发者用 OpenClaw 搭建了一整套数据采集系统。虽然听起来有点夸张,但实际上这种事情在开源社区里还挺常见的。
这也说明一个问题——工具本身的潜力,往往取决于使用者的想象力。
持续获取资源的方法
订阅更新与官方通知
学习工具有一个很容易被忽略的事情:版本更新。
OpenClaw 的开发节奏其实挺快的,很多功能都会在新版本里逐渐完善。如果不关注更新,很可能会错过一些非常实用的新功能。
比较简单的方法包括:
- 关注官方仓库更新
- 订阅发布日志
- 查看更新说明
有时候一条更新日志,可能就隐藏着一个很重要的新功能。
加入学习社区与讨论组
最后,其实我非常推荐的一件事情,就是加入社区。
说实话,很多真正实用的技巧,并不是从教程里学到的,而是从社区交流中慢慢积累的。
在一些技术社区里,你经常会看到这样的场景:有人提出一个问题,几分钟之后就会有好几个不同的解决方案。这种讨论氛围其实非常有价值。
当然,社区不仅仅是提问的地方,也是分享经验的地方。等你熟悉 OpenClaw 之后,说不定也能帮助到其他人。
回头来看,学习 OpenClaw 其实并没有想象中那么困难。关键在于找到合适的资源,再加上一点点耐心和探索精神。官方文档、社区经验、第三方插件,这些内容结合起来,就像拼图一样慢慢构成完整的知识体系。只要保持持续学习的习惯,很多原本看起来复杂的功能,最后都会变得顺手自然。
常见问题
OpenClaw是如何帮助开发者提高工作效率的?
OpenClaw提供高度开放的功能,可以根据个人需求定制和扩展,帮助开发者优化工作流程并提高效率。
哪些人群最适合使用OpenClaw?
OpenClaw适合对自动化工具感兴趣的开发者、希望优化工作流程的技术人员、喜欢折腾开源项目的学习者,以及需要灵活工具链的团队。
OpenClaw的学习曲线如何?
OpenClaw提供高度的自由度,这意味着需要一些时间来适应和掌握其核心功能,学习曲线相对较陡,但一旦熟悉后,使用起来会非常高效。
如何找到OpenClaw的最新学习资源?
可以通过OpenClaw的官方网站、相关论坛以及国外社区获取最新的学习资源和技巧。
OpenClaw是否适合只想简单完成任务的用户?
如果用户只需一键完成任务的工具,OpenClaw可能不太适合,因为它的设计更倾向于提供定制化和灵活性。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/72929.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















{kind=link}