


在如今这个快速发展的 AI 时代,如何高效地管理和部署人工智能团队已经成为每个企业不得不面对的问题。OpenClaw 作为一个开源的 AI 代理框架,不仅能够让多智能体协作更加顺畅,还能优化业务流程与自动化任务执行。本文将带你深入探索从团队评估到平台部署、从协作分工到持续改进的完整路线图,帮助老板和开发者更好地理解 OpenClaw 的实际应用价值,并为打造高效 AI 团队提供切实可行的策略。
引言:为什么选择 OpenClaw
AI 团队效率的挑战
说到 AI 团队效率,这个问题其实比表面上看起来要复杂得多。我个人观察到,很多团队在协作中常常遇到的困扰并非技术本身,而是沟通不畅、角色模糊以及工具碎片化。尤其是在多任务同时进行时,往往会出现重复劳动或资源浪费的情况。你有没有想过,同样一群开发者和数据科学家,效率可能天差地别,仅仅因为缺少一个统一的协作平台?
此外,AI 项目的特殊性在于数据、模型和流程高度耦合,一旦流程设计不合理,错误会被无限放大。这让我想到,效率问题其实不仅是“做得快”,更是“做得对”。
OpenClaw 的核心优势
OpenClaw 之所以被越来越多团队关注,原因在于它提供了一个多 Agent 协作框架,让不同角色的智能体能够清晰分工、无缝协作。更有意思的是,它不仅覆盖了安装部署,还包括消息接入和权限管理,极大降低了技术门槛和风险。同时,OpenClaw 的生态技能扩展丰富,你可以把它想象成一个可以持续“升级”的协作大脑。换句话说,它不仅是工具,更是一种团队运作方式的优化。
准备阶段:评估与规划
团队现状评估
在动手之前,我总喜欢先画一张“全景图”,看看团队现状。你会发现,有些人擅长模型训练,有些人擅长数据处理,还有些人擅长系统部署。实际上,这一步是为了避免盲目堆技术堆人,而是让每个角色都能发挥最大效能。值得注意的是,这种评估不光是技能层面的,也包括团队的沟通方式、项目管理习惯和现有工具链。
项目目标与需求定义
定义目标听起来简单,但实际上经常被低估。我个人认为,目标的清晰度直接影响到后续每一步的决策。如果你只说“提升 AI 效率”,团队可能会各自理解不同的“效率”。所以,我建议把目标拆解成可量化的指标,比如任务完成时间、错误率或自动化覆盖率,这样才能有迹可循。
技术栈与资源准备
谈到技术栈,我往往会结合团队现有技能与项目需求来选择。OpenClaw 支持本地部署和云部署,这给了我们灵活性。根据我的观察,本地部署更适合数据敏感型企业,而云部署则便于快速迭代和扩展。此外,提前准备好必要的计算资源、网络环境和权限配置,可以避免后期一堆琐碎问题,让部署过程顺畅得多。
实施阶段:OpenClaw 上手指南
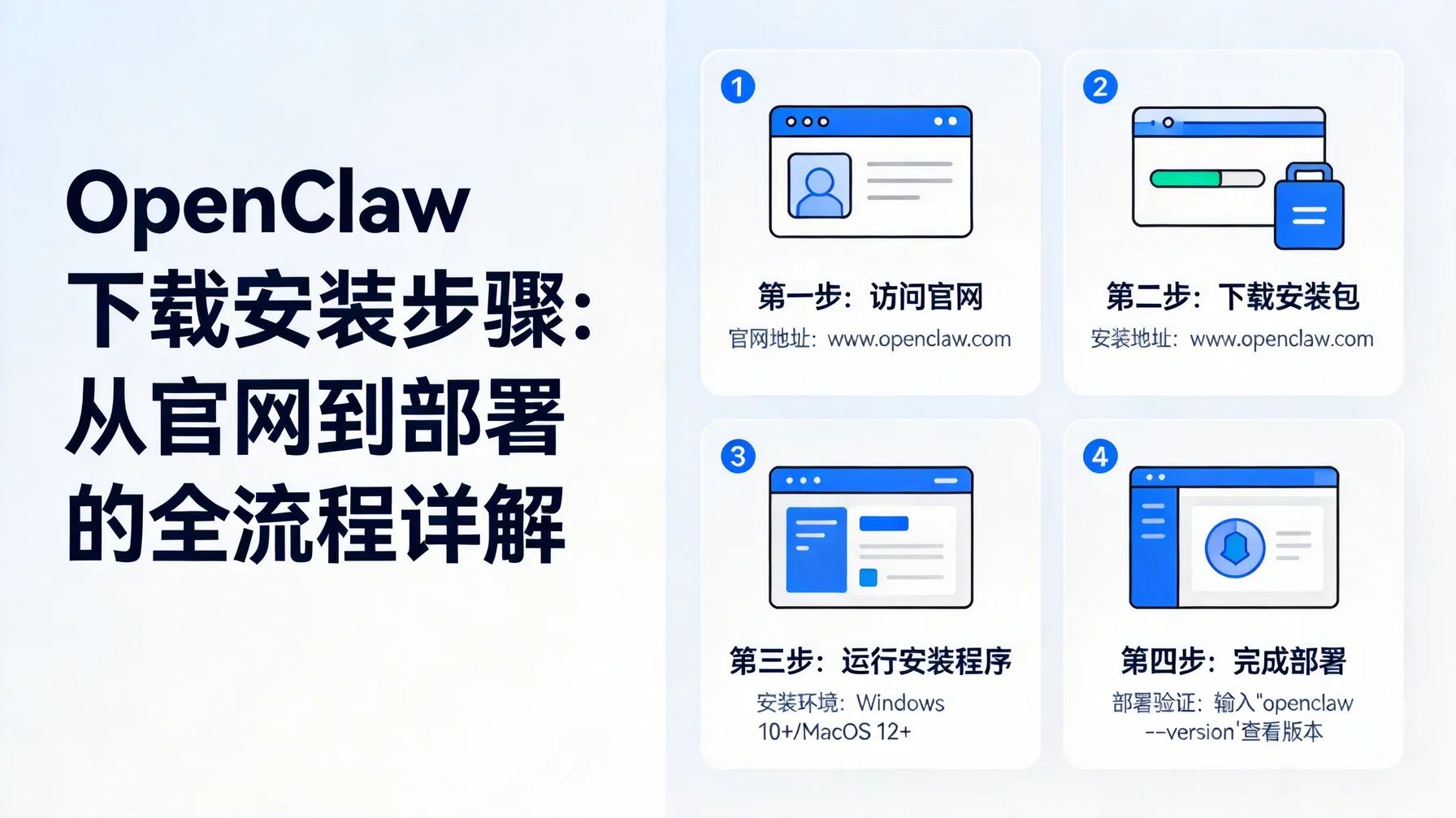
平台安装与配置
安装 OpenClaw 的过程比我最初想象的要直观,但也不能掉以轻心。你需要关注依赖环境、网络配置以及权限管理。我个人建议先在测试环境跑一遍完整流程,这样一旦迁移到正式环境就不会出现大规模崩溃。顺便提一下,日志配置和监控也是不能忽视的环节,它能让你及时发现问题,而不是等到项目停滞才追查。
核心功能模块解析
OpenClaw 的核心模块主要包括任务分配、多 Agent 协作、消息接入和权限管理。这里有意思的是,多 Agent 协作并不是简单地把任务拆分,而是根据每个 Agent 的特长和技能动态分配任务。这让我想到,就像一个乐队,每个乐器都有自己的节奏,只有协调得当,才能奏出和谐的乐章。
数据管理与训练流程优化
数据管理一直是 AI 项目中的“隐形杀手”。OpenClaw 提供了统一的数据接口和流程管理,实际上可以让团队更专注于模型优化而不是数据搬运。我个人经验是,把数据标注、清洗、训练流程形成闭环,会大幅提升团队效率。虽然有点跑题,但这也让我反思,很多团队真正浪费的时间,其实是在重复处理不必要的基础工作。
团队协作与管理优化
角色与职责分配
在团队协作中,我发现明确的角色和职责能减少绝大部分摩擦。OpenClaw 支持对不同 Agent 设定不同权限,这不仅保障了安全,也让每个成员知道自己的边界和责任。换句话说,分工越明确,协作越顺畅,而这正是高效团队的核心要素。
敏捷开发与迭代管理
敏捷并不是口号,而是一种思维方式。OpenClaw 的迭代机制让我体会到,快速试错、持续优化远比一次性追求完美更重要。在实际操作中,我个人喜欢用短周期迭代,每次小幅更新,快速收集反馈,这样整个团队都能保持高度灵活。
沟通与知识共享机制
沟通和知识共享常常被低估。我个人体会是,无论技术多先进,如果团队知识壁垒太高,效率依旧低下。OpenClaw 支持统一的消息系统和技能文档,我会建议团队把经验总结形成可复用的模块,让新成员上手更快,同时减少重复劳动。
性能提升与持续改进
指标监控与分析
指标监控对我来说像是 AI 团队的“健康体检”。OpenClaw 提供了多维度的性能数据,让我们可以量化任务完成效率、错误率以及协作情况。我个人建议,把这些指标和团队目标绑定,只有看到具体数据,才能真正发现瓶颈并加以优化。
自动化与工具链优化
自动化是提高效率的加速器。我观察到,当团队把重复性操作交给 Agent,成员可以把精力集中在创造性工作上。OpenClaw 的技能扩展能力正好支持这种做法,你可以像搭积木一样把不同模块组合成高效工作流。这让我想到,如果每个团队都能善用这种方式,AI 项目的节奏可能会完全不一样。
经验总结与最佳实践沉淀
每次项目结束,我都会建议团队总结经验。OpenClaw 让这些实践可以以模块化形式保存和复用,这一点非常宝贵。我个人认为,这不仅仅是为了效率,更是为了打造一种“可持续成长”的团队文化。
案例分析:成功的 OpenClaw AI 团队实践
企业实例解析
有一家企业,我亲自观察过,他们用 OpenClaw 建立了多 Agent 协作团队,涵盖数据标注、模型训练到部署监控各环节。令人惊讶的是,他们不仅提高了整体效率,还能在短时间内快速应对突发问题。这里让我意识到,技术本身的价值往往体现在实际落地的效果上,而不是理论上多么完美。
关键成功因素总结
总结来看,成功的关键在于三点:明确分工、良好沟通和持续优化。OpenClaw 提供了工具和机制,但真正让它生效的,是团队对流程的理解与执行。我个人觉得,这一点比技术本身更重要。
结语:迈向高效 AI 团队的未来
持续学习与创新
AI 团队的成长没有终点。我个人认为,持续学习和创新是保持竞争力的根本。OpenClaw 的开放性和扩展性,恰好为团队提供了不断尝试和改进的平台。换句话说,只要思路够灵活,你的团队永远有机会不断提升。
OpenClaw 的发展前景
展望未来,OpenClaw 不仅会在技术层面持续进化,更可能成为 AI 团队协作的新标准。值得注意的是,这不是空想,而是基于它的开源特性、技能扩展能力以及成熟的协作框架。对我来说,它就像一个不断成长的实验室,既可以探索新方法,也可以验证旧经验。
总体来看,OpenClaw 为打造高效 AI 团队提供了完整路径,从评估规划到实施管理,再到持续优化和案例借鉴,每一步都值得深思。通过科学分工、敏捷迭代和知识沉淀,团队不仅能提升效率,更能形成可持续发展的能力。这篇文章希望能为老板和开发者提供切实参考,让 AI 团队的建设少走弯路,迈向真正高效与协作的未来。
常见问题
OpenClaw 能为 AI 团队带来哪些优势?
OpenClaw 提供多智能体协作框架,有效解决团队沟通不畅、角色模糊等问题,提升协作效率并优化工作流程。
如何评估 AI 团队的现状并制定相应规划?
首先需要对团队成员的技能和任务进行评估,确保每个成员的角色定位清晰,避免资源浪费和重复劳动。
OpenClaw 如何降低技术门槛和风险?
OpenClaw 提供易于部署的框架,涵盖安装、消息接入和权限管理,帮助团队降低技术难度并减少部署风险。
如何通过 OpenClaw 实现 AI 团队的持续改进?
OpenClaw 提供丰富的技能扩展功能,团队可以不断升级协作平台,优化工作流程和技术应用,从而实现持续改进。
多智能体协作框架与传统团队协作有何不同?
多智能体协作框架通过明确分工与无缝协作,避免了传统团队中因沟通不畅或角色不清晰而导致的低效与混乱。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/72939.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















{kind=link}