


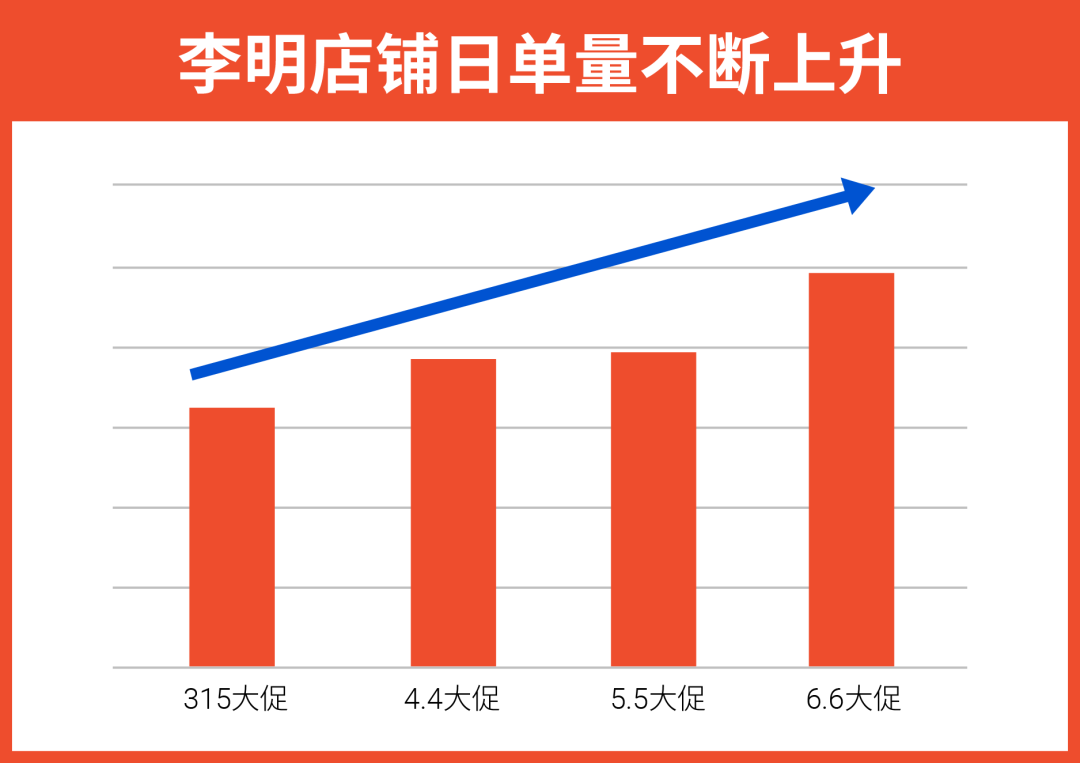
现在,还没发布大模型的科技公司,在行业里已经显得有点非主流了。
微软和OpenAI联手烧起来的大模型之火还没燃完一个月,国内大模型已经开始卷起来。今年四月可以称为国内大模型的肇始之月。继百度在3月底发布文心一言后,阿里、腾讯、字节等行业巨头,以及商汤、知乎等细分领域玩家都陆续发布了自己的大模型产品。
科技公司扎堆大模型,这次真的不能怪它们喜欢抢热点。
除了资本市场热捧ChatGPT概念所能带来的短期资本效应外,向市场发布大模型的更重要意义,在于让产品能够源源不断地吸收到最新的数据和用户反馈,进而转动数据、技术互相驱动的飞轮。也就是说,谁先下场,谁就最有可能在实际场景里实现技术赶超。
一众发布了大模型的公司中,4月17日正式发布的千亿级大语言模型“天工”是话不多的那一个,却公开表示“天工”3.5是第一个真正实现智能涌现的国产大语言模型,已“非常接近OpenAI ChatGPT的智能水平”。
“天工”大模型由昆仑万维和AI团队奇点智源共同打造,作为一家上市公司,昆仑万维给予了旗下大模型非常高的评价,“天工”表现到底如何?我们特地测了测。







此外,天工在实时性的事实回答上表现尤为突出。比如,天工知道最近的烧烤顶流是淄博。这意味着天工的训练数据更新十分及时,且天工对信息的提炼总结能力也是到位的。





不符合市场的一贯认知。甚至在官方推文中,昆仑万维自己也说“很多人不相信昆仑万维能做出大模型”。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/35011.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















































{kind=link}