


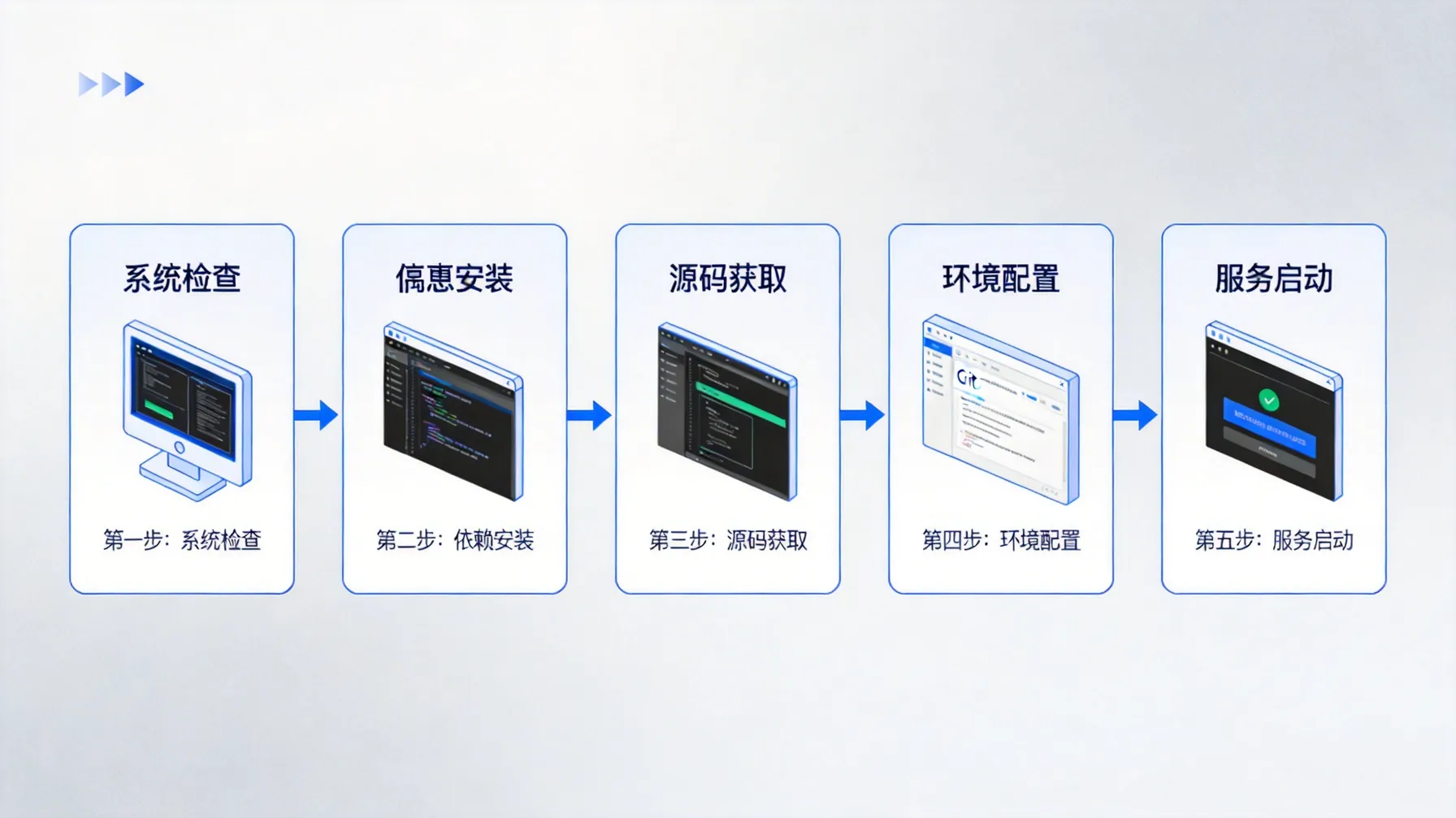
在当下人工智能和自动化工具快速发展的背景下,本地部署OpenClaw已成为很多开发者和技术爱好者关注的焦点。要知道,直接在本地运行不仅能提升响应速度,还能更好地保护数据隐私,这在许多项目中尤其重要。本文将从头到尾带你走一遍OpenClaw的完整部署流程,从系统准备、环境配置到安装运行,甚至包括调优和扩展技能的建议。即便你是第一次尝试,也能通过这篇指南掌握核心步骤,少走弯路。
OpenClaw简介
OpenClaw的功能与特点
说到OpenClaw,它给人的第一印象可能是名字很有力,其实功能也的确如此。简单来说,OpenClaw是一个集AI模型管理、技能扩展以及本地服务运行于一体的工具。它可以让你轻松加载不同的AI模型,并通过Clawdbot等接口实现多种自动化操作。让我觉得有意思的是,它不仅支持云端模型,还能配合本地Ollama进行模型调用,这在数据敏感或者网络不稳定的场景下特别有用。
从个人体验来看,OpenClaw的灵活性是最大的亮点。你可以根据需求调整模型优先级,也可以通过技能扩展让原本单一的服务变得更加智能和互动。换句话说,它不仅是一个工具,更像是一个可持续成长的AI平台。
适用场景与优势
我常常会想,如果你手头有大量需要本地处理的数据,又不希望它们被发送到外部服务器,那么OpenClaw几乎是唯一的选择。它适合本地数据分析、智能问答、自动化任务执行等多种场景。值得注意的是,对于企业或个人开发者来说,部署在本地还能节省网络开销,同时提供更高的安全性。
有时候,我甚至把它当作一个实验平台来测试不同模型的表现。你可以随时切换不同的技能和配置,而不必担心云端的延迟或限制。这种自由度,是很多在线服务无法比拟的。
本地部署前的准备
硬件与系统要求
部署前,我个人习惯先检查硬件和操作系统环境。虽然OpenClaw本身对资源需求不算极端,但为了流畅运行,建议至少有一台内存16GB以上的机器,CPU尽量支持多线程。你有没有想过,如果内存不足,模型加载时可能会卡顿或者直接报错?这是我在早期实验中踩过的坑。
操作系统方面,我发现Linux环境下的稳定性最佳,但Windows和MacOS同样可行。只不过,Linux在依赖管理和网络配置上更灵活一些。
必要软件与依赖安装
说到依赖,Node.js、PNPM、Git几乎是必不可少的。Docker虽然可选,但我个人认为在做容器化测试或跨环境部署时,它能省掉不少麻烦。安装这些软件时,我喜欢一步步确认版本号,避免后续出现奇怪的兼容性问题。顺便提一下,网络不稳定的情况下,某些依赖下载可能会中断,所以提前准备好镜像或者离线安装包会更省心。
获取OpenClaw安装包或源码
拿到安装包其实是个小插曲。我通常会先选择稳定的版本,而不是最新的开发版本。虽然最新版本可能有新功能,但也可能带来未知的bug。下载完成后,解压或克隆源码到本地指定目录,确保路径不要含有空格或中文,这点在Windows系统上尤其重要。
OpenClaw环境配置
Python环境配置
虽然OpenClaw主要是Node.js驱动,但Python环境仍然很重要,尤其是一些模型处理和数据预处理环节。个人建议使用虚拟环境来隔离依赖,避免和系统Python库产生冲突。我自己习惯用venv或者conda来创建环境,这样每次实验都可以干干净净,不会互相影响。
数据库初始化与配置
数据库配置这一块,我曾经犯过一个小错误,就是忘记初始化某些表,结果运行时报错。经验告诉我,无论是SQLite还是PostgreSQL,提前执行初始化脚本是必须的。值得注意的是,OpenClaw的Clawdbot依赖数据库来存储技能和模型信息,如果数据库配置不当,很多功能无法正常使用。
网络与端口设置
网络设置其实有点微妙。默认端口一般是安全的,但如果你的机器上已经有其他服务占用,就会冲突。我个人习惯先用netstat或者lsof检查端口占用情况,然后再调整OpenClaw配置文件。顺便提一句,如果计划远程访问服务,还要考虑防火墙规则,这一点很多新手容易忽略。
OpenClaw安装步骤
源码编译与安装
源码安装对我来说总带着一点仪式感。解压源码后,先安装依赖,再执行编译命令。让我惊讶的是,OpenClaw的安装过程相对顺畅,没有太多复杂步骤。唯一需要注意的,是不同操作系统的路径差异和权限问题,这些小细节往往决定安装是否成功。
使用安装脚本快速部署
如果你不想手动处理每一步,官方提供的安装脚本确实省心很多。我个人用过几次,一般只要保证依赖安装完整,运行脚本就能完成大部分配置。不过,我也会先看看脚本里到底做了哪些操作,毕竟自己清楚背后的流程总比盲目执行更有安全感。
常见安装问题及解决方案
安装过程中最容易碰到的,通常是依赖冲突或权限问题。有时候Node.js版本不对,PNPM安装失败,或者某些系统库缺失。这让我想到,提前查看日志并保持耐心是关键。经验告诉我,遇到问题不要慌,逐条检查错误提示,通常都能找到解决办法。
首次运行与测试
启动OpenClaw服务
启动服务那一刻,总有点小紧张。键入启动命令后,屏幕上滚动的日志信息让我有点期待又有点担心。值得庆幸的是,如果前期准备充分,启动过程通常很顺利。这个阶段,我会特别关注启动是否报错,以及端口监听是否正常。
验证功能是否正常
启动后,验证是必不可少的环节。我会先用简单的模型调用测试,确保Clawdbot可以响应请求,技能扩展也能正常加载。实际上,有时候问题可能并不在OpenClaw本身,而是在模型路径或配置文件上,所以验证环节不能省略。
日志查看与故障排查
日志是朋友也是救星。我个人习惯把日志输出到单独文件,方便分析。遇到异常行为时,先看日志往往能快速定位问题。记住,很多故障不是系统问题,而是配置上的小疏忽,比如端口错了或者数据库未初始化。
进阶配置与优化
性能优化建议
性能优化其实是个持续过程。我个人经验是,从调整内存分配、线程数到合理管理模型缓存,都能明显提升响应速度。特别是处理大型模型时,如果不优化内存和计算资源,很容易出现卡顿甚至崩溃。
安全性配置
安全性配置对我来说一直很重要。即便是在本地运行,设置访问权限、防火墙规则和敏感数据隔离也不容忽视。我个人建议,为不同技能和模型配置独立的访问策略,这样即便出现问题,也能降低风险。
自动化管理与维护
长期运行OpenClaw,需要一定的自动化管理。我喜欢设置定时任务或使用脚本自动备份数据库、清理缓存,这样可以让系统保持稳定。虽然这些操作不复杂,但能大幅减少手动维护的烦恼。
总结与常见问题
部署流程回顾
回顾整个流程,从环境检查到依赖安装,再到源码配置和服务启动,每一步都至关重要。个人体会是,越是前期准备充分,后续遇到的问题越少。换句话说,细节决定成败。
常见问题汇总
结合我的经验,新手最容易碰到的主要问题包括依赖冲突、端口占用、数据库未初始化以及权限问题。遇到这些问题,耐心查看日志,逐条排查,通常都能解决。值得强调的是,不要急于修改核心文件,先搞清楚问题原因再动手,总比盲目操作安全得多。
参考资料与社区资源
我个人建议,多关注OpenClaw官方文档和活跃社区,那里不仅有最新的更新信息,还有很多实践经验分享。尤其是在处理一些非标准环境或者尝试高级功能时,社区的经验往往比官方文档更直接有效。
总的来说,本地部署OpenClaw虽然过程细节较多,但只要按部就班,掌握关键步骤,完全可以顺利完成。从环境准备到安装测试,再到性能优化和安全配置,每一环节都是保障系统稳定运行的关键。希望这篇文章能帮助你少走弯路,更快体验到OpenClaw带来的高效与便利。
常见问题
OpenClaw的系统要求是什么?
OpenClaw推荐至少配备16GB内存的机器,操作系统需为Linux、Windows或macOS,确保流畅运行。
如何进行OpenClaw的技能扩展?
技能扩展通过Clawdbot接口进行,用户可以根据需求加载不同的AI模型并优化配置。
本地部署OpenClaw有哪些优势?
本地部署能够提升响应速度、保护数据隐私,同时避免网络不稳定带来的问题,适合需要高安全性和高效率的项目。
是否可以将OpenClaw用于多个模型的测试?
是的,OpenClaw提供灵活的模型切换功能,可以用于不同AI模型的性能对比测试。
OpenClaw支持哪些数据类型的处理?
OpenClaw支持本地数据分析、智能问答、自动化任务执行等多种数据类型的处理。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/72398.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















































{kind=link}