


企业级部署概述
Claude Code 在企业环境中的定位
首先,我们得搞清楚一件事:Claude Code在企业里到底扮演什么角色?我个人认为,它不应该只是一个“高级的代码补全工具”,更不是用来替代开发者的。它的核心价值,在于成为开发团队的“超级副驾驶”——帮你处理那些重复性高、逻辑清晰但耗时巨大的任务,比如代码审查、文档生成、测试用例编写,甚至是遗留系统的重构分析。
有意思的是,很多企业一开始把它定位错了,把它当成一个“万能答案机”,结果发现它在处理高度定制化的业务逻辑时,表现并不理想。这让我想到一个比喻:Claude Code更像是一个经验丰富的“高级工程师助理”,而不是一个“全知全能的架构师”。你需要给它清晰的指令和上下文,它才能发挥最大价值。所以,部署之前,先想清楚你到底要它干什么,这比任何技术选型都重要。
部署模式选择:云端 vs 本地
这个选择,可以说是企业级部署的第一个分水岭。云端部署的优势很明显——几乎不用操心基础设施,弹性伸缩能力一流,而且能第一时间享受到模型更新带来的红利。但问题也摆在那里:数据要经过第三方服务器,对于一些金融、医疗、军工等对数据主权有严格要求的行业,这简直是红线。
本地部署呢?数据完全在自己手里,安全可控,延迟也更低。但代价是,你得自己搞定GPU服务器、网络、运维,而且模型更新往往有滞后性。更现实的问题是,本地部署的成本可能高得吓人,尤其是当你需要支持高并发时。根据我的经验,没有绝对的“最优解”,只有“最适合你的解”。我见过一些企业采用混合模式——核心敏感数据走本地,非核心业务走云端,这或许是一个值得考虑的折中方案。
企业级部署的核心挑战
说到核心挑战,我总结下来无非三点:安全、性能、成本。但有趣的是,这三个东西往往是相互制约的。你想更安全,加密和审计流程一多,性能就下来了;你想性能好,堆更多的GPU,成本就上去了;你想省钱,用更少的资源,响应速度又慢了。这就像是一个不可能三角,你只能在其中找到那个微妙的平衡点。
另一个容易被忽视的挑战是“人”。再好的工具,如果团队不会用、不敢用、不想用,那它就是一堆废铁。部署Claude Code,不仅仅是技术问题,更是一个管理问题。你需要培训、需要制定规范、需要建立信任。说实话,这比搞定技术难题要难得多。
安全控制要点
数据隐私与合规性要求
安全这个话题,我得先泼一盆冷水:没有任何系统是绝对安全的,我们能做的,只是无限接近那个目标。对于Claude Code来说,数据隐私是重中之重。你想啊,代码里包含了多少商业机密、算法逻辑、数据库结构?一旦泄露,后果不堪设想。
合规性方面,不同行业有不同要求。比如GDPR要求用户数据不能随意出境,HIPAA要求医疗信息必须加密存储。我的建议是,在部署前,一定要和法务、合规部门坐在一起,把红线划清楚。不要等到出了事再补救,那时候就晚了。具体操作上,可以考虑数据脱敏、本地化存储、以及严格的访问控制策略。
身份认证与访问控制策略
谁可以用Claude Code?能用它做什么?这两个问题,是身份认证和访问控制要解决的。我个人比较推荐基于角色的访问控制(RBAC)模型。比如,普通开发者只能调用代码补全和审查功能,而项目经理可以查看用量报告,管理员才能修改配置。
另外,多因素认证(MFA)几乎是必须的。别嫌麻烦,这能挡住90%的暴力破解和凭证泄露攻击。还有一个细节容易被忽略:API密钥的管理。很多团队把API密钥硬编码在代码里,或者放在共享文档中,这简直是给攻击者送大礼。一定要用密钥管理服务,定期轮换,并设置最小权限原则。
代码与敏感信息脱敏处理
这是我最想强调的一点。Claude Code在处理代码时,可能会接触到数据库密码、API密钥、内部IP地址等敏感信息。如果不做脱敏处理,这些信息就可能被模型“记住”,甚至在不经意间泄露给其他用户。
具体怎么做呢?我的经验是,在将代码发送给模型之前,先经过一个“脱敏层”。这个层可以用正则表达式或专门的工具,把敏感信息替换成占位符。比如,把真实的数据库密码替换成${DB_PASSWORD}。等模型返回结果后,再反向替换回来。虽然这增加了处理延迟,但为了安全,这点代价是值得的。
审计日志与安全监控
你永远不知道谁会犯错,但你可以确保自己知道谁犯了错。审计日志就是干这个的。每一次API调用、每一次模型输出、每一次配置变更,都应该被记录下来。而且,这些日志不能只存不查,你需要建立一套监控规则。
举个例子,如果某个用户在一分钟内调用了1000次Claude Code,这明显是异常行为,可能是被攻击了,也可能是脚本出了问题。这时候,监控系统应该能自动触发告警,甚至临时冻结该用户的权限。说实话,事后复盘时,审计日志是你最好的朋友。
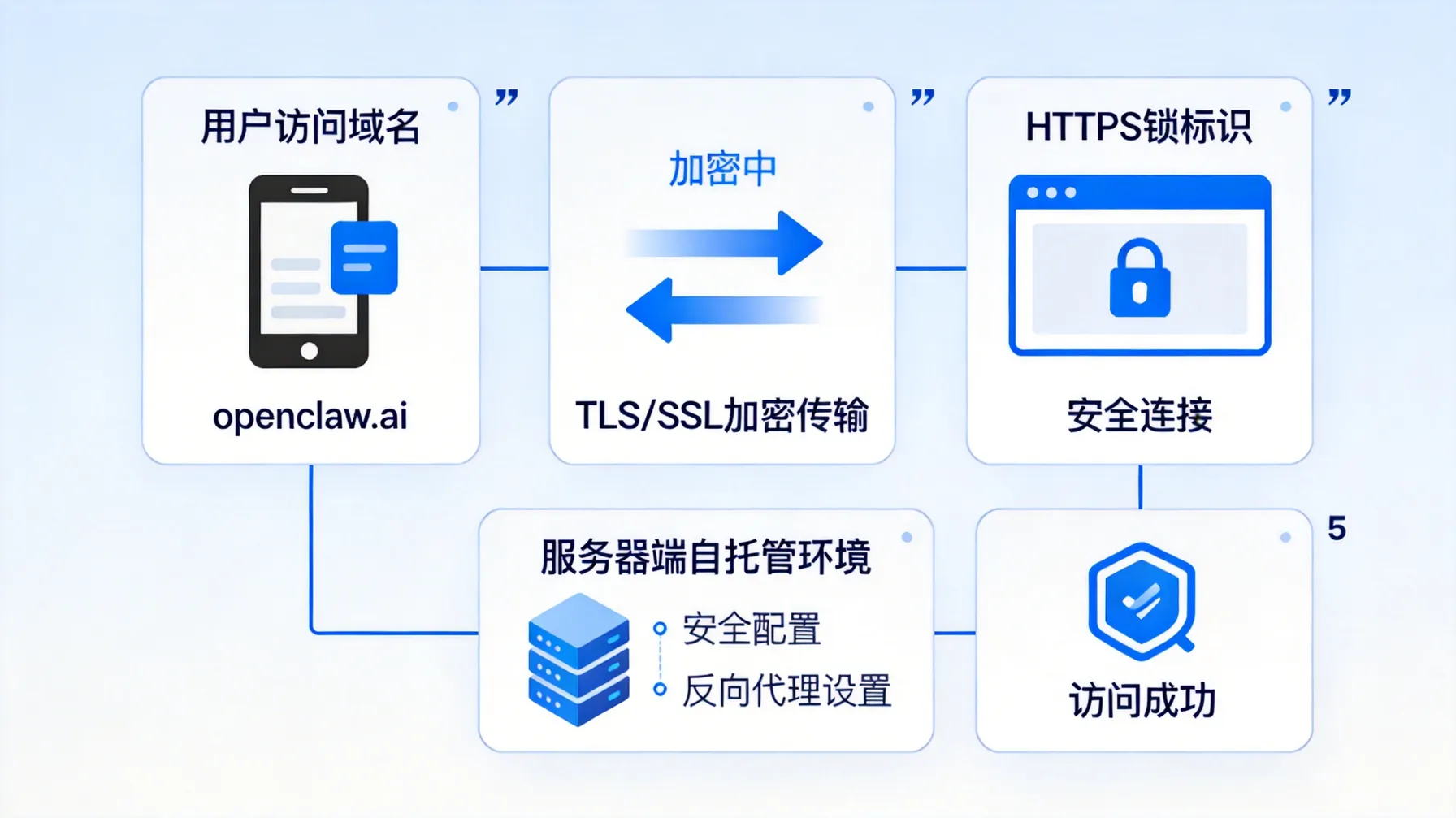
网络隔离与API安全防护
Claude Code的API应该只暴露给内网,或者通过VPN访问。千万不要图方便,直接把它挂在公网上。另外,API请求一定要做速率限制(Rate Limiting),防止恶意攻击或误操作导致服务过载。
还有一个点:HTTPS是必须的,但别忘了启用HSTS(HTTP Strict Transport Security),防止中间人攻击。如果你用的是云端部署,还要考虑WAF(Web应用防火墙)的配置,过滤掉SQL注入、XSS等常见攻击。
性能优化策略
模型推理延迟优化
说到性能,第一个想到的就是延迟。用户发出请求,到模型返回结果,这中间的等待时间,直接决定了用户体验。模型推理延迟主要受两个因素影响:模型大小和硬件性能。
对于本地部署,我建议优先考虑使用量化后的模型。比如,把FP16的模型量化成INT8,推理速度能提升2-3倍,而精度损失几乎可以忽略。另外,使用TensorRT或ONNX Runtime这样的推理优化引擎,也能显著降低延迟。云端部署的话,选择靠近用户区域的服务器节点,能减少网络传输时间。
并发请求与负载均衡
当你的团队规模扩大,并发请求量就会上来。这时候,单台服务器肯定扛不住。你需要引入负载均衡器,把请求分发到多台推理服务器上。这里有一个坑:模型推理是计算密集型任务,不是简单的请求转发,所以负载均衡策略不能是简单的轮询。
我比较推荐基于“当前负载”的动态调度。比如,每台服务器在启动时,向注册中心报告自己的剩余处理能力。负载均衡器根据这个信息,把新请求分配给最空闲的服务器。这样能最大化资源利用率,避免某些服务器过载而其他服务器闲置。
缓存机制与响应加速
你有没有想过,很多请求其实是重复的?比如,同一个代码审查任务,不同的开发者可能会提交类似的代码片段。如果每次都让模型重新推理一遍,那太浪费了。引入缓存机制,能大幅提升响应速度。
具体来说,可以用Redis或Memcached,把模型输入和输出作为键值对缓存起来。当新请求到来时,先计算输入内容的哈希值,然后在缓存中查找。如果命中,直接返回结果,延迟几乎为零。当然,缓存要有过期时间,防止数据过时。而且,对于敏感信息,缓存要加密存储。
资源弹性伸缩方案
业务量是有波峰波谷的。白天上班时间,请求量可能很大;到了晚上,又变得很少。如果按峰值配置资源,那成本会高得离谱。弹性伸缩就是解决这个问题的。
对于云端部署,Kubernetes的Horizontal Pod Autoscaler(HPA)可以自动根据CPU/GPU利用率或请求量,增加或减少推理Pod的数量。对于本地部署,虽然弹性伸缩没那么灵活,但可以通过虚拟化技术,在空闲时把GPU资源分配给其他任务。我见过一些企业,把Claude Code的推理集群和训练集群共用,白天跑推理,晚上跑训练,资源利用率直接翻倍。
性能基准测试与监控
没有基准测试,你永远不知道自己的系统到底有多快。在部署前,一定要做压力测试,摸清系统的极限在哪里。比如,在单台服务器上,每秒能处理多少个请求?平均延迟是多少?P99延迟是多少?这些数据,是你做容量规划的基础。
监控方面,我建议关注几个关键指标:请求量、延迟分布、错误率、GPU利用率、内存占用。用Prometheus+Grafana搭建监控面板,一目了然。一旦发现某个指标异常,比如延迟突然飙升,就要立刻排查原因。
成本控制方法
Token消耗分析与优化
Claude Code是按Token计费的,所以控制Token消耗就是控制成本。但很多人不知道,Token消耗是可以优化的。比如,输入给模型的上下文越长,消耗的Token就越多。所以,尽量精简输入,只提供必要的信息。
另一个技巧是,使用“系统提示词”来引导模型输出更简洁的答案。比如,在提示词中加入“请用不超过200字回答”,能有效减少输出Token。还有,对于重复性任务,可以缓存模型的输出,避免重复计算。根据我的经验,通过这些优化,Token消耗能降低30%-50%。
按需分配与资源池管理
不是所有用户都需要同样的服务质量。比如,核心开发团队可能需要低延迟、高并发的服务,而测试团队可能只需要偶尔用一下。如果一视同仁,那成本就上去了。
我的建议是,建立资源池,按需分配。比如,设置“金级”、“银级”、“铜级”三个服务等级。金级用户享有专用GPU资源,银级用户共享资源但有优先级,铜级用户则在空闲时才能使用。这样,既能保证核心业务的性能,又能控制整体成本。
预算预警与用量限制
成本失控,往往是因为没有预警机制。你设置了一个月10万的预算,结果到了月底才发现已经花了20万,那就晚了。所以,一定要设置预算预警。比如,当用量达到预算的80%时,自动发送邮件通知;达到100%时,自动限制非核心用户的使用。
另外,用量限制也很重要。比如,每个用户每天最多调用100次Claude Code,或者每次请求的最大Token数不能超过4096。这些限制,能防止个别用户滥用资源,导致整体成本失控。
混合部署降低成本
我之前提到过混合部署,这里再展开说说。混合部署的核心思路是:把高敏感、高频率的任务放在本地,把低敏感、低频率的任务放在云端。这样,本地服务器的规模可以控制得比较小,而云端则按需付费,避免了资源浪费。
举个例子,代码审查任务需要频繁调用Claude Code,而且涉及敏感代码,适合放在本地。而文档生成任务,不涉及敏感信息,且调用频率低,可以放在云端。通过这种方式,我见过一些企业把总成本降低了40%以上。
长期成本模型与ROI评估
最后,别忘了算一笔长期的账。Claude Code的部署成本,不仅仅是服务器和API费用,还包括人力成本、运维成本、培训成本。你需要建立一个成本模型,预测未来1-3年的总支出。
同时,也要评估ROI。Claude Code到底能为企业带来多少价值?比如,开发效率提升了多少?代码质量提高了多少?Bug率降低了多少?这些数据,是说服管理层继续投入的关键。说实话,如果ROI算不清楚,这个项目很难长久。
部署实施最佳实践
基础设施选型建议
基础设施选型,我建议遵循“够用就好”的原则。不要一上来就买最贵的GPU,先评估一下你的实际需求。比如,如果你的团队只有10个人,并发请求量不大,那么一块NVIDIA A100或者RTX 4090就足够了。如果团队有100人,那可能需要多块A100或者H100。
存储方面,SSD是必须的,因为模型加载和缓存读写都需要高速IO。网络方面,建议使用25Gbps以上的网卡,减少数据传输瓶颈。还有一个容易被忽略的点:散热和电力。GPU服务器的功耗很高,一定要确保机房有足够的散热能力和电力供应。
CI/CD集成与自动化部署
Claude Code的部署,不应该是一个手动操作的过程。它应该集成到你的CI/CD流水线中。比如,当代码更新时,自动触发Claude Code的模型重新加载;当配置变更时,自动执行灰度发布。
我推荐使用GitOps的方式,把部署配置存储在Git仓库中,通过ArgoCD或Flux这样的工具,自动同步到生产环境。这样,每一次变更都有记录,可以追溯,也方便回滚。
灰度发布与回滚策略
新版本上线,最怕的就是出问题。灰度发布能帮你把风险降到最低。比如,先让5%的流量走新版本,观察一段时间,如果没有异常,再逐步扩大到10%、50%、100%。
同时,一定要有回滚策略。一旦发现新版本有问题,能在一分钟内切回旧版本。我的建议是,保留最近三个版本的镜像,并准备好回滚脚本。另外,数据库的变更也要考虑回滚,比如使用Flyway或Liquibase这样的工具管理数据库迁移。
多环境管理(开发/测试/生产)
开发、测试、生产环境,一定要严格隔离。开发环境可以随便折腾,但生产环境必须稳定。我的经验是,使用不同的Kubernetes命名空间或不同的集群来管理。
环境之间的配置差异,用ConfigMap和Secret来管理。比如,开发环境使用模拟数据,生产环境使用真实数据。还有,测试环境要尽量模拟生产环境的负载,否则测试结果没有参考价值。
运维监控与告警体系
运维不是等出了事再救火,而是要在出事前就发现苗头。监控体系要覆盖三个层面:基础设施层(CPU、内存、网络)、应用层(请求量、延迟、错误率)、业务层(Token消耗、用户活跃度)。
告警规则要设置合理,避免“狼来了”效应。比如,延迟超过500ms持续5分钟才告警,而不是一有波动就告警。另外,告警通知要分级,P0级告警直接打电话给值班人员,P3级告警只发邮件。
常见问题与解决方案
模型幻觉与输出质量控制
模型幻觉,是AI领域的通病。Claude Code有时候会生成一些看起来合理但实际上错误的代码。怎么解决?我的建议是,不要完全信任模型输出。
首先,在提示词中加入“请基于事实回答,不要编造信息”。其次,对模型输出进行后处理,比如用静态代码分析工具检查语法错误。最后,建立人工审核机制,对于关键代码,必须由资深开发者审核后才能合并。
跨团队协作与权限管理
当多个团队共用一套Claude Code时,权限管理就变得复杂了。比如,A团队的代码不能让B团队看到。这时候,你需要实现“租户隔离”。
我的做法是,为每个团队创建一个独立的“工作空间”,每个工作空间有自己的配置、缓存和日志。团队之间完全隔离,互不可见。权限管理方面,使用LDAP或OAuth集成企业已有的身份系统,统一管理用户和角色。</
常见问题
Claude Code在企业中的主要用途是什么?
Claude Code的核心定位是开发团队的辅助工具,而非替代品。它擅长处理代码审查、文档生成、测试用例编写和遗留系统重构分析等重复性高、逻辑清晰的任务,需要清晰的指令和上下文才能发挥最大价值。
部署Claude Code时,云端和本地模式如何选择?
云端部署无需操心基础设施,弹性伸缩能力强,能及时获得模型更新;但数据需经过第三方服务器,对金融、医疗、军工等对数据主权有严格要求的行业可能不适用。本地部署则能完全控制数据,但需要自行管理硬件和运维成本。选择取决于企业的安全合规要求和资源投入能力。
企业部署Claude Code时常见的成本陷阱有哪些?
常见成本陷阱包括:初期过于乐观,未充分评估模型调用频率和token消耗;忽视基础设施(如GPU、存储)的持续投入;以及因定位错误导致频繁调整指令和上下文,增加不必要的调用次数。建议先明确使用场景,进行小规模试点,再逐步扩展。
如何确保Claude Code在企业环境中的数据安全?
数据安全需从多个层面入手:选择符合企业合规要求的部署模式(如本地或私有云);对敏感数据进行脱敏处理;限制模型对内部系统的访问权限;定期审计日志和调用记录。对于金融、医疗等高度监管行业,建议优先考虑本地部署并配合加密传输。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/73600.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




















{kind=link}