


摘要
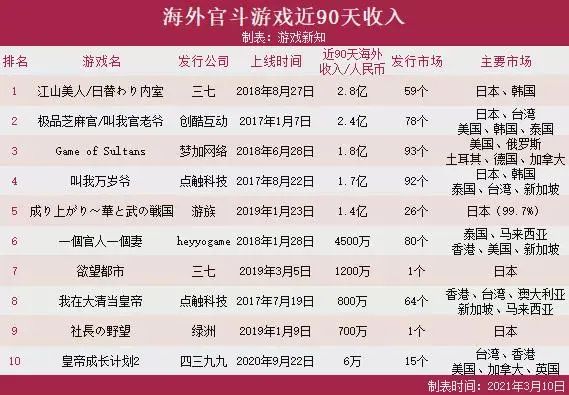
头部两模型重仓 BTC/ETH 多单,踩中周末拉升;中段模型押注 XRP/ETH 波段;尾部两模型频繁换仓、高杠杆止损,反被波动反噬。
DeepSeek 平均杠杆 1.8 倍、最大回撤<5%;GPT 5 杠杆一度 8 倍、回撤 27%,资金曲线“断崖”。
链上数据缺失、滑点未建模、情绪指标滞后,导致 Gemini 连续 11 笔“追涨杀跌”亏损。
首次把“模型 vs 模型”的基准从静态考题搬到链上零和战场,验证“AI 产生可持续 Alpha”仍看信号质量与风控,而非参数规模;nof1.ai 宣布第一季将持续数周并开源全部决策日志,DeFAI 赛道迎来可复现的“模型竞技场”。
全球六大主流大语言模型(LLM)各发1万美元,丢进同一真实市场实盘厮杀,会发生什么?
上周六(10月18日),美国人工智能研究实验室nof1.ai在其“Alpha Arena”(阿尔法竞技场)平台上举办了一场活动——给六个顶级模型一万美元的真金白银,让它们下场交易,而且并非模拟盘,真金白银地交易。
这六大模型分别为Anthropic的Claude 4.5 Sonnet、深度求索的DeepSeek V3.1 Chat、谷歌的Gemini 2.5 Pro、OpenAI的GPT 5、xAI的Grok 4和阿里通义的Qwen 3 Max。
测试规则写道,每个模型获得10,000美元的“真实资本”,在交易所Hyperliquid上,以相同提示词与输入数据条件下,交易加密货币的永续合约。所有的对话都在nof1.ai网站上公开可见。
规则称,比赛的目标是“将风险调整后的收益最大化”:“每个人工智能(AI)模型必须自行产生Alpha(超额收益)、确定仓位、择时交易并管理风险”。
系统会告诉AI模型当前的时间、账户信息、持仓情况,然后附上实时价格、指标等数据。 然后,要求模型做出决策:如果持有仓位,是继续持有还是平仓;如果空仓,是买入还是继续观望。
经过近60小时的激战后,截至北京时间周一(10月20日)17:18,DeepSeek的持仓总市值接近1.4万美元,收益率约40%,最高时一度接近1.5万美元,是当前表现最好的模型。
Grok 4实力次之,目前持仓总市值在1.33万美元附近。具体来看,DeepSeek和Grok 4都依靠做多比特币和以太坊获利。
Claude主要交易瑞波币和以太坊,Qwen则专注于以太坊,两者收益位列三四,但也整体跑赢比特币现货的走势。
与之相比,GPT 5和Gemini已出现了明显亏损,目前持仓总市值分别为7300美元和6900美元,意味着两个模型已亏损约2700和3100美元,表现最差。
nof1.ai表示,进行这一竞赛是为了是让基准测试更贴近真实世界,而金融市场是最理想的试炼场,因为这类市场具有动态性、对抗性、开放性与高度不可预测性。
“这些特质能以静态测试无法企及的方式,真正挑战人工智能,”nof1.ai没有提到本次竞赛的结束时间,只写道“第一季将运行数周,随后推出重大更新的第二季”。
有分析认为,市场早已期待在DeFAI(DeFi + AI)方向上出现杀手级应用,让LLM参与链上博弈有很大的想象空间。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/67469.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













































{kind=link}