


引言:为什么选择 Codex API 进行智能编码集成
你可能也遇到过这种情况:写代码的时候,脑子里明明有思路,但手就是跟不上。或者更糟糕的是,你卡在一个不熟悉的库或者 API 上,翻文档翻到怀疑人生。Codex API 的出现,某种程度上就是为了解决这些痛点。它不只是一个“自动补全”工具,它能理解自然语言描述,然后生成对应的代码。这听起来很酷,但真正把它用好,其实需要一些技巧。
Codex API 的核心能力与适用场景
我个人觉得,Codex 最厉害的地方在于它能处理“模糊”的需求。比如你跟它说“写一个函数,读取 CSV 文件并返回前五行数据”,它不仅能生成代码,还能考虑到各种边界情况。当然,它也不是万能的。如果你需要处理非常复杂的业务逻辑,或者涉及大量领域知识,Codex 可能会给出一些看似正确但实际上有问题的代码。这时候就需要我们开发者来把关了。
说到适用场景,我自己的经验是,它最适合那些“重复性高但逻辑不复杂”的任务。比如生成模板代码、写单元测试、甚至是帮你重构一些老代码。有意思的是,我最近发现它还能用来写一些简单的脚本,比如自动化处理日志文件,效果出奇的好。
与传统编码辅助工具相比的优势
传统的代码补全工具,比如 IDE 自带的那些,基本是基于语法分析和历史输入来预测。它们很聪明,但有时候会显得有点“死板”。Codex 不一样,它背后是一个大语言模型,能理解上下文和意图。举个例子,你跟它说“用 Python 写一个快速排序”,它不会只给你一个函数签名,而是会把整个实现逻辑都给你,甚至还会加上注释。
当然,这也不是说传统工具就没用了。实际上,我觉得它们更像是互补的关系。传统工具在处理局部细节上更精准,而 Codex 在宏观理解和生成上更有优势。如果你能把两者结合起来,效率提升可不是一点半点。
本文目标读者与预期收获
这篇文章主要是写给那些有一定编程基础,但对 Codex API 还不太熟悉的开发者。不管你是后端、前端还是数据科学家,只要你想把 AI 编码能力集成到自己的工作流里,这篇文章应该能帮到你。读完以后,你至少能知道怎么配置环境、怎么构造有效的 Prompt、怎么处理常见的错误,以及怎么在实际项目中用起来。
说实话,我写这篇文章的时候,也一直在想,到底什么样的内容对读者最有价值。后来我想明白了,与其堆砌一堆理论,不如把我在实际项目中踩过的坑、总结出的经验分享出来。这样大家读起来会更有代入感,也能更快地上手。
准备工作:环境与权限配置
在开始之前,有一件事得先搞定——那就是环境配置。别看这一步好像很简单,实际上很多人就是在这里卡住了。我当初第一次配置的时候,也花了不少时间,主要是对 OpenAI 的文档不太熟悉。不过别担心,跟着我一步步来,应该很快就能搞定。
注册 OpenAI 账号并获取 API Key
第一步当然是注册 OpenAI 账号。这个流程其实挺简单的,去官网点个注册,填个邮箱,验证一下就完事了。但有一点要注意:OpenAI 现在对 API 的使用是有审核机制的,尤其是 Codex 这种比较高级的模型。所以注册完后,你可能需要申请一下 Codex 的访问权限。这个过程有时候会等几天,别着急,耐心等待就好。
拿到 API Key 以后,记得把它保存好。我个人习惯是放到环境变量里,这样既安全又方便。千万不要硬编码到代码里,尤其是如果你打算把代码开源的话,那可就出大事了。
安装必要的开发工具与依赖库
接下来就是安装工具了。如果你用的是 Python,那最常用的就是 openai 这个库。安装命令很简单:pip install openai。但说实话,我建议你最好用虚拟环境来安装,这样可以避免跟系统级的 Python 包冲突。
除了 Python,你还可以用其他语言,比如 Node.js 或者 Go。OpenAI 官方都提供了对应的 SDK,用起来也挺方便的。不过我个人还是推荐 Python,因为它的生态更成熟,社区资源也更多。
理解 Codex 模型(如 code-davinci-002)的差异
说到模型,这里有个小知识点得说一下。Codex 其实有多个版本,比如 code-davinci-002 和 code-cushman-001。它们之间的区别主要在于能力和成本。davinci 系列是最强大的,但也是最贵的;cushman 系列便宜一些,但能力也弱一点。
我的建议是,初期可以先试试 davinci,感受一下它的上限在哪里。等你对 Prompt 的构造有了一定经验,再考虑切换到 cushman 来降低成本。当然,这也不是绝对的,具体用哪个还得看你的实际需求。
设置 API 调用频率与配额限制
这个点很容易被忽略,但我觉得非常重要。OpenAI 的 API 是有调用频率限制的,如果你短时间内发太多请求,可能会被限流。所以最好在代码里加一个简单的限流机制,比如用 time.sleep() 来控制请求间隔。
另外,配额限制也得注意。OpenAI 会根据你的账号等级给你分配一定的免费额度,用完了就得付费了。所以建议你在开发阶段先设置一个较低的配额,避免不小心花太多钱。
核心集成步骤:从零搭建基础工作流
好了,环境配置好了,接下来就是真正干活的时候了。这一部分我会详细讲讲怎么从零开始搭建一个基础的 Codex 工作流。说实话,这一步并不复杂,但有一些细节需要注意,不然很容易出问题。
构造有效的 Prompt 以提升代码生成质量
Prompt 的构造可以说是整个流程中最关键的一环。一个好的 Prompt,能让 Codex 生成出高质量的代码;一个差的 Prompt,可能会让你得到一堆乱七八糟的东西。我的经验是,Prompt 要尽量具体,最好能给出输入输出示例。比如你想让 Codex 写一个排序函数,不要只说“写一个排序”,而是说“写一个函数,输入一个整数列表,返回升序排列的结果”。
另外,还可以在 Prompt 里加入一些约束条件,比如“不要使用第三方库”或者“时间复杂度要控制在 O(n log n)”。这样 Codex 生成出来的代码会更符合你的预期。
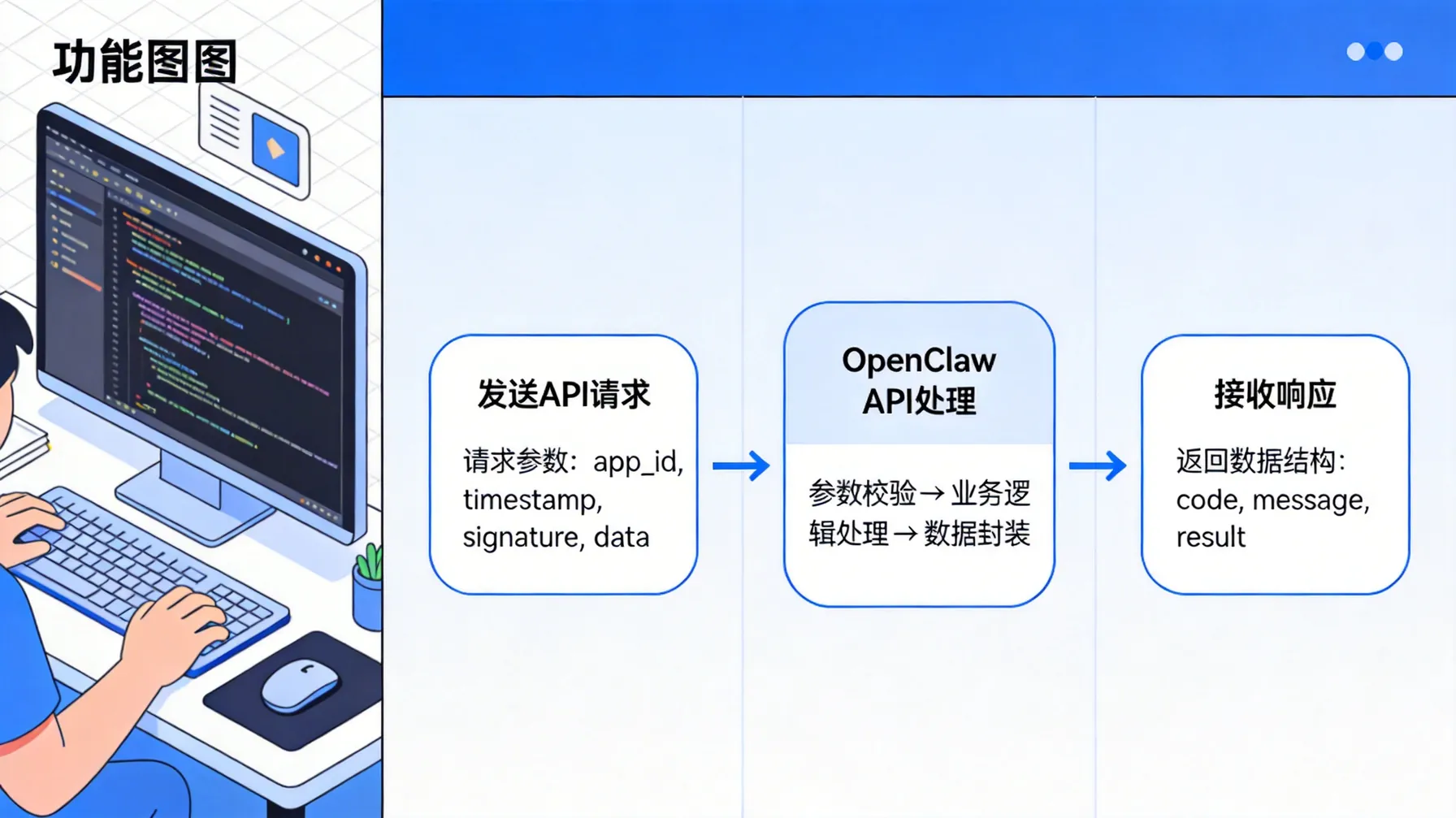
处理 API 请求与响应的最佳实践
发送 API 请求其实很简单,就是调用一下 openai.Completion.create() 方法。但处理响应的时候,有几个坑需要注意。首先,响应里可能会包含多个候选结果,你得根据 choices 字段来提取最合适的那一个。其次,响应里的 text 字段可能包含一些额外的空格或者换行符,建议做一下清理。
还有一点,就是要注意响应的长度。如果你设置的 max_tokens 太小,Codex 可能只生成了一半的代码就停了。所以建议根据任务复杂度来合理设置这个参数。
错误处理与重试机制
网络请求嘛,难免会遇到各种错误。比如超时、连接失败、或者 API 返回错误代码。我的建议是,一定要在代码里加上重试机制。比如用 tenacity 这个库,可以很方便地实现指数退避重试。
但要注意,不是所有错误都值得重试。比如 400 错误(Bad Request),说明你的 Prompt 有问题,重试多少次都没用。这时候应该检查一下 Prompt 的格式。而 500 错误(Server Error)则可能是 OpenAI 那边的问题,重试几次通常能解决。
流式输出(Streaming)实现实时反馈
如果你想让用户体验更好一点,可以考虑用流式输出。简单来说,就是让 Codex 一边生成代码一边返回结果,而不是等全部生成完再一次性返回。这样用户能看到代码一点一点地出现,感觉就像有人在实时打字一样。
实现起来也不复杂,只需要在请求里加上 stream=True 参数,然后通过迭代器来逐块处理响应。不过要注意,流式输出会增加网络开销,所以如果你的网络环境不太好,可能会有点卡顿。
进阶技巧:优化智能编码工作流
基础工作流搭建好了以后,接下来就是怎么让它变得更高效、更智能。这一部分我会分享一些进阶技巧,这些技巧是我在实际项目中摸索出来的,希望能给你一些启发。
利用上下文窗口管理长对话与代码片段
Codex 的上下文窗口是有限的,比如 code-davinci-002 的窗口大小是 8000 个 token。如果你的对话太长,或者代码片段太大,就可能超出限制。这时候就需要做一些管理了。
我的做法是,把不重要的历史对话删掉,只保留最近几轮的关键信息。或者把长代码片段拆分成多个小片段,分别处理。另外,还可以用一些压缩技巧,比如把注释去掉,或者用缩写代替长变量名。
结合代码补全与解释功能提升效率
Codex 不仅能生成代码,还能解释代码。这个功能其实很实用,尤其是当你接手别人的代码,或者想快速理解一个复杂算法的时候。你可以先让 Codex 生成代码,然后再让它解释一下关键部分,这样理解起来会快很多。
我有时候还会反过来用:先让 Codex 解释一段代码,然后再根据解释来修改它。这种方式特别适合调试,因为 Codex 的解释往往能帮你发现一些逻辑上的问题。
使用温度(Temperature)与 Top-p 参数控制输出
这两个参数是用来控制 Codex 输出的随机性的。温度越高,输出越随机;温度越低,输出越确定。我的经验是,对于代码生成这种任务,温度最好设低一点,比如 0.2 左右。这样 Codex 会更倾向于生成“标准”的代码,而不是一些奇怪的变体。
Top-p 参数的作用类似,但它是基于概率分布的。一般来说,如果你想让 Codex 更“保守”,可以把 Top-p 设小一点;如果你想让 Codex 更有“创意”,可以设大一点。不过说实话,对于代码生成,我很少用 Top-p,主要还是靠温度来控制。
缓存常用结果以减少 API 调用成本
API 调用是要花钱的,所以能省则省。一个很实用的技巧就是缓存。比如你经常需要生成某种模板代码,可以把第一次生成的结果缓存起来,下次直接取用,不用再调用 API。
实现起来也很简单,可以用 Redis 或者本地文件来存储缓存。关键是设置好缓存的有效期,避免缓存过期后还在用旧数据。另外,缓存键的设计也很重要,最好能精确匹配 Prompt 的内容,避免缓存冲突。
安全与合规:保护代码与数据隐私
说到安全,这其实是一个很容易被忽视但非常重要的话题。毕竟,你要把代码发给 OpenAI 的服务器去处理,这里面可能涉及一些敏感信息。所以,怎么保护代码和数据隐私,是我们必须认真对待的。
避免在 Prompt 中泄露敏感信息
这个点我觉得怎么强调都不为过。千万不要在 Prompt 里包含任何敏感信息,比如数据库密码、API Key、或者个人身份信息。如果你不小心泄露了,后果可能会很严重。
我的做法是,在发送请求之前,先对 Prompt 做一次检查,把那些看起来像敏感信息的内容替换成占位符。比如把真实密码替换成 ******,这样既不影响 Codex 的理解,又能保护隐私。
数据脱敏与本地预处理策略
除了避免泄露,还可以做一些主动的数据脱敏。比如把代码里的真实用户名、邮箱地址替换成虚拟数据。这样即使数据被泄露,也不会造成实际损失。
另外,我建议尽量在本地做一些预处理。比如把代码里的注释去掉,或者把变量名简化一下。这样不仅能减少 API 调用的数据量,还能降低泄露风险。
理解 OpenAI 的数据使用政策
OpenAI 的数据使用政策其实挺透明的,但很多人可能没仔细看。简单来说,OpenAI 不会用你的数据来训练模型,除非你明确同意。但有一点要注意:如果你用的是免费额度,OpenAI 可能会保留你的数据用于安全审查。
所以,如果你处理的是非常敏感的数据,建议购买付费套餐,这样数据保护会更严格。另外,也可以考虑用 OpenAI 的私有部署方案,不过那个成本会高很多。
实施访问控制与日志审计
最后,别忘了在系统层面做一些访问控制。比如限制只有特定 IP 才能调用 API,或者给不同的用户分配不同的 API Key。这样即使某个 Key 泄露了,影响范围也能控制住。
日志审计也很重要。建议记录每次 API 调用的时间、用户、以及 Prompt 的摘要。这样万一出了问题,可以快速定位到责任人。
实际案例:构建一个代码审查助手
说了这么多理论,我觉得还是用一个实际案例来收尾比较好。这个案例是我最近在做的——一个基于 Codex 的代码审查助手。说实话,这个项目让我对 Codex 的能力有了更深的理解。
需求分析与工作流设计
需求其实很简单:每次提交代码之前,自动对代码进行审查,找出潜在的问题。比如变量命名不规范、缺少注释、或者存在安全漏洞。工作流设计也很直接:提交代码 -> 调用 Codex 审查 -> 生成审查报告 -> 人工确认。
但真正做起来,我发现事情没那么简单。比如,怎么让 Codex 理解“规范”这个词?不同的团队有不同的规范,所以需要把规范文档也作为 Prompt 的一部分传进去。
集成 Codex API 实现自动代码审查
集成过程其实跟前面讲的基础工作流差不多。关键是要构造一个有效的 Prompt。我试过很多种写法,最后发现最有效的是:先给 Codex 一段代码,然后问它“这段代码有什么问题?请列出所有潜在的问题,并给出修改建议。”
有意思的是,Codex 不仅能找出语法问题,还能发现一些逻辑上的错误。比如有一次,它发现了一个死循环,而那个 bug 我看了半天都没发现。
结果展示与人工审核闭环
审查结果不能直接拿来用,必须经过人工审核。我的做法是,把 Codex 生成的审查报告展示在一个页面上,然后让开发者逐条确认。确认通过的,自动修复;有争议的,人工讨论。
这个闭环设计很重要,因为 Codex 也不是万能的。有时候它会给出一些不合理的建议,比如把一段完全正确的代码改错了。所以人工审核是必须的。
性能评估与迭代优化
项目上线后,我一直在跟踪它的性能。比如,Codex 的审查准确率是多少?每次审查需要多长时间?成本是多少?这些数据都很重要,可以帮助我们不断优化。
根据我的统计,目前 Codex 的审查准确率大概在 80% 左右。虽然不算完美,但已经能帮我们节省大量时间了。下一步,我打算尝试用多模型协作的方式,比如让不同的模型审查不同的方面,看看能不能把准确率再提高一些。
常见问题与故障排除
在实际使用中,你肯定会遇到各种问题。这一部分我整理了一些常见的问题和解决方法,希望能帮你少走一些弯路。
API 返回空结果或错误代码的处理
这个问题最常见的原因就是 Prompt 不符合要求。比如你忘了设置 max_tokens,或者 temperature 设得太低。还有一种可能是 API Key 过期了,或者你的账号被限流了。
我的建议是,先检查一下请求参数,然后看看 OpenAI 的官方文档,确认一下错误代码的含义。如果还是解决不了,可以去 OpenAI 的社区论坛求助,那里有很多热心的开发者。
模型输出不符合预期的调试方法
常见问题
Codex API 能处理复杂的业务逻辑吗?
Codex API 更适合处理重复性高但逻辑不复杂的任务,如模板代码生成、单元测试编写等。对于复杂业务逻辑或涉及大量领域知识的场景,生成的代码可能需要开发者仔细审查和调整。
Codex API 与传统代码补全工具有什么区别?
传统工具基于语法分析和历史输入预测,而 Codex API 能理解自然语言描述,生成对应代码,更像一个协作搭档。它擅长处理模糊需求,但需要开发者对输出进行把关。
如何开始使用 Codex API 搭建编码工作流?
首先获取 API 密钥,然后根据官方文档集成到开发环境中。建议从简单任务开始,如生成模板代码或脚本,逐步探索其在重构、测试等场景的应用,并注意验证生成的代码质量。
Codex API 在哪些场景下效果最好?
最适合重复性高但逻辑不清晰的任务,例如生成模板代码、编写单元测试、重构老代码,以及自动化处理日志文件等简单脚本。对于需要大量领域知识的复杂逻辑,效果可能有限。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://www.siyushenqi.com/73596.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




















{kind=link}